

Supervised machine learning uses labeled data to train algorithms. It predicts outcomes based on input-output pairs.
Supervised machine learning is essential in data science. It involves training algorithms with labeled datasets to make accurate predictions. This method is widely used in various applications, including fraud detection, medical diagnosis, and customer segmentation. By analyzing historical data, supervised learning models can identify patterns and make data-driven decisions.
Techniques such as classification and regression are common in this field. Classification deals with categorizing data into predefined classes, while regression predicts continuous values. Implementing supervised machine learning can significantly enhance the accuracy and efficiency of data-driven tasks, making it a cornerstone of modern data science practices.
Credit: www.geeksforgeeks.org
Introduction To Supervised Machine Learning
Supervised Machine Learning for Data Science involves training algorithms on labeled datasets to make accurate predictions. This approach enhances data-driven decision-making by leveraging historical data to identify patterns and trends.
Core Concepts
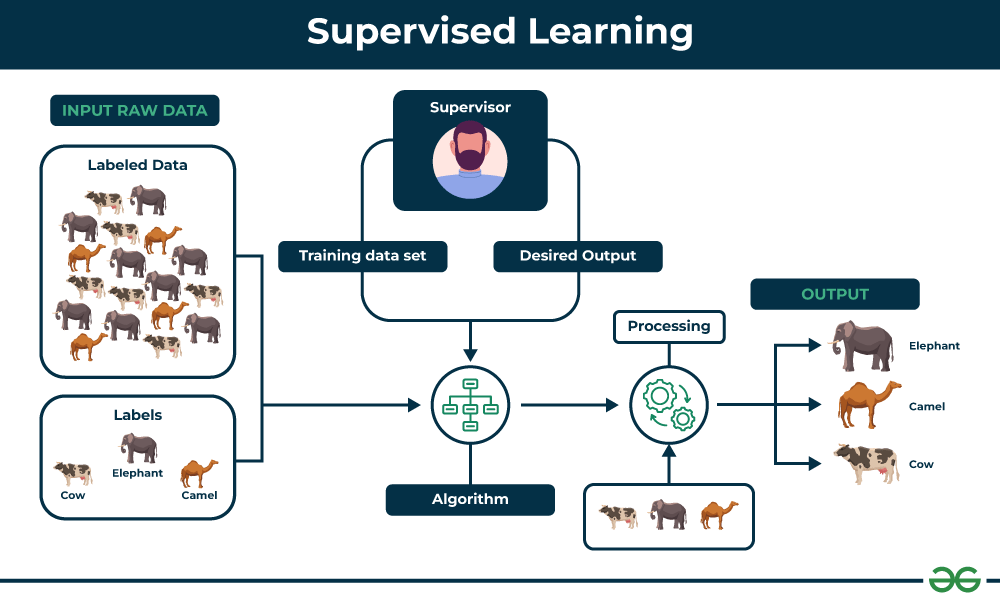
Supervised machine learning involves teaching a computer. The computer learns from labeled data. Labeled data means data with answers. The computer uses this data to make predictions. There are two main types of tasks: classification and regression. Classification predicts categories, like spam or not spam. Regression predicts numbers, like house prices. Training and testing are key steps. Training uses data to learn. Testing checks how well it learned. The goal is to make accurate predictions.
Real-world Applications
Supervised machine learning is used in many areas. Email filtering is one example. It sorts emails into spam and non-spam. Medical diagnosis is another example. It helps doctors find diseases. Stock market prediction uses it to guess future prices. Voice recognition turns speech into text. Image recognition finds objects in pictures. These applications make our lives easier.
Types Of Supervised Learning
Classification tasks are about predicting a category. For example, classifying emails as spam or not spam. Another example is identifying images of cats and dogs. These tasks use labeled data to learn from. The model learns to map input data to specific categories. Successful classification means the model can correctly identify the category of new data.
Regression tasks involve predicting a numerical value. For instance, predicting the price of a house based on its features. Another example is forecasting sales figures for the next month. These tasks also use labeled data to learn patterns. The goal is to predict continuous values accurately. Good regression models minimize the difference between predicted and actual values.
Key Algorithms In Supervised Learning
Linear regression helps predict values. It uses a straight line to make predictions. This line is called the regression line. The line shows the relationship between variables. It is simple and easy to understand.
Decision trees split data into branches. Each branch represents a decision. The tree helps make choices based on data. It is like a flowchart. Nodes in the tree show decisions or outcomes. Leaves are the final results.
Support Vector Machines (SVM) classify data into groups. They find the best line or plane to separate data. This line is called the hyperplane. SVM works well with high-dimensional data. It is powerful for complex tasks.
Data Preparation Steps
Data preparation steps in supervised machine learning for data science involve collecting, cleaning, and transforming raw data. Ensuring data quality and relevance helps improve model accuracy and performance.
Cleaning Data
Cleaning data is very important. It helps remove errors and inconsistencies. This step ensures the data is accurate. Missing values need to be handled. Duplicate entries should be removed. Outliers must be identified and treated. Consistent data types are necessary for analysis. Clean data leads to better models.
Feature Selection
Feature selection is crucial. It picks the most important features. This step reduces the complexity of the model. Irrelevant features can confuse the model. Good features improve the model’s performance. There are various methods for feature selection. Some methods are statistical tests and algorithms. Proper feature selection leads to more accurate predictions.
Model Training And Validation
Model training and validation play crucial roles in supervised machine learning for data science. These processes ensure models make accurate predictions by learning from labeled data and evaluating their performance on unseen data.
Training Sets And Testing Sets
Training sets are used to teach the model. Testing sets are used to check the model’s accuracy. Both sets must be different. Training helps the model learn patterns. Testing ensures the model works well on new data. Always keep the data in separate sets. This prevents overfitting. Overfitting means the model is too good at training data but bad at new data.
Cross-validation Techniques
Cross-validation is a way to check the model’s performance. It uses different parts of the data for training and testing. One common method is k-fold cross-validation. Here, the data is split into k smaller sets. The model trains on k-1 sets and tests on the remaining set. This process is repeated k times. The results are then averaged to get a final score. This technique helps ensure the model is reliable.

Credit: www.amazon.com
Evaluating Model Performance
Accuracy metrics help to measure how well a model performs. The most common metric is accuracy. It shows the ratio of correct predictions to total predictions. Another important metric is precision. It tells us how many selected items are relevant. Recall measures how many relevant items are selected. F1 score combines precision and recall into one number. Higher values mean better performance.
A confusion matrix is a tool to see the performance of a model. It has four parts: True Positive (TP), True Negative (TN), False Positive (FP), and False Negative (FN). TP is when the model correctly predicts a positive class. TN is when the model correctly predicts a negative class. FP is when the model wrongly predicts a positive class. FN is when the model wrongly predicts a negative class.
Overcoming Overfitting And Underfitting
Regularization helps prevent models from overfitting. It adds a penalty to the model complexity. L1 and L2 are popular regularization techniques. L1 regularization can lead to sparse models. L2 regularization helps in reducing the impact of outliers. Combining both can be very effective. Regularization is crucial in improving model performance.
Pruning helps in reducing the size of decision trees. It removes nodes that add little predictive power. Pre-pruning stops the tree growth early. Post-pruning removes nodes after the tree is fully grown. Pruning helps in preventing overfitting. It makes the model more generalizable. Proper pruning improves accuracy and efficiency.
Advanced Topics In Supervised Learning
Neural networks are a key part of supervised learning. They are like the brain of a computer. Neurons in a network work together to solve complex problems. Each neuron processes data and passes it to the next one. This process helps the network learn from data. Neural networks can recognize images, understand speech, and even play games. They are used in many real-world applications.
Ensemble learning combines multiple models to improve accuracy. It uses different methods like bagging, boosting, and stacking. Bagging trains several models on different data samples. Boosting focuses on errors from previous models. Stacking uses predictions from multiple models to create a final model. Ensemble methods are powerful because they reduce errors and increase model stability.
Case Studies
Explore compelling case studies showcasing the impact of supervised machine learning in data science. Learn how predictive models drive insightful data analysis and enhance decision-making. Discover real-world applications transforming industries through advanced algorithmic techniques.
Healthcare Predictive Analytics
Supervised machine learning helps doctors predict patient outcomes. This improves patient care. For example, it can predict disease outbreaks. Early detection saves lives. It also helps in personalizing treatments. Each patient gets the best care for their needs. Hospitals reduce costs by preventing unnecessary treatments. Medical staff make better decisions with accurate data. Patient records get analyzed quickly. This saves time and effort. Supervised learning models grow smarter over time.
Financial Market Prediction
Investors use supervised machine learning to predict market trends. This helps in making better investments. Algorithms analyze historical data. They spot patterns that humans may miss. Predicting stock prices becomes more accurate. Risk gets minimized with better forecasts. It helps in detecting fraudulent activities. Financial institutions save money and maintain trust. Traders get real-time insights. This improves their decision-making process. Financial markets become more stable with precise predictions.

Credit: www.geeksforgeeks.org
Future Trends In Supervised Learning
AutoML helps automate the process of machine learning. It reduces the need for deep technical knowledge. Data scientists can focus on important tasks. AutoML handles tasks like model selection and hyperparameter tuning. It makes machine learning more accessible. Businesses can benefit from faster insights. AutoML is expected to grow rapidly in the coming years.
Explainable AI makes machine learning models easier to understand. It helps users trust the predictions made by these models. Explainable AI provides insights into how decisions are made. This is important for industries like healthcare and finance. Users can identify and correct biases in the models. Explainable AI ensures transparency in machine learning processes.
Frequently Asked Questions
What Is Supervised Machine Learning In Data Science?
Supervised machine learning involves training models using labeled data. It predicts outcomes based on learned patterns. This technique is essential for tasks like classification and regression. Supervised learning improves accuracy and efficiency in data-driven decisions.
What Are Supervised Learning Algorithms Towards Data Science?
Supervised learning algorithms use labeled data to train models. They predict outcomes based on input-output pairs. Examples include linear regression, decision trees, and support vector machines. These algorithms are essential for classification and regression tasks in data science.
What Is An Example Of Supervised Learning?
An example of supervised learning is email spam detection. Algorithms classify emails as spam or not based on labeled data.
Where Machine Learning Is Used In The Data Science Process?
Machine learning is used in data preprocessing, model building, and evaluation. It helps in predicting outcomes and uncovering patterns.
Conclusion
Supervised machine learning is crucial for data science. It helps in making accurate predictions and informed decisions. By understanding its algorithms, you can unlock data’s full potential. Start exploring supervised learning today to stay ahead in the data-driven world. Embrace this technology to transform your data science projects.