Unlock the potential of recurrent neural networks in NLP. Learn about LSTM, GRU, and state-of-the-art language models. Improve your text analysis and generation skills. Click to master RNNs for NLP!
Recurrent Neural Networks (RNNs) revolutionize natural language processing (NLP) by effectively handling sequential data. Unlike traditional neural networks, RNNs maintain a memory of previous inputs, enabling them to capture context and dependencies in language. This ability makes RNNs particularly suited for tasks like language modeling, text generation, and machine translation.
Their architecture allows them to process variable-length sequences, making them versatile for diverse NLP applications. By leveraging RNNs, developers can build more sophisticated models that understand and generate human language more naturally. These networks are foundational for advancements in AI-driven language technologies, driving innovations in communication, translation, and information retrieval.
Credit: machinelearningmastery.com
7 RNN Techniques For Your NLP Projects
- The RNN Revolution: Understanding the Basics
First things first, let’s break down what RNNs are all about. These clever neural networks are designed to handle sequential data, making them perfect for tackling language tasks. Unlike their simpler cousins, RNNs have a built-in memory that allows them to consider previous inputs when processing new information.
FAQ: What makes RNNs different from other neural networks? Answer: RNNs have a unique ability to maintain internal state and process sequences of data, making them ideal for tasks involving time series or natural language.
Key Point: RNNs are the go-to choice for many NLP tasks due to their ability to handle context and long-term dependencies in text.
- LSTM Networks: The Memory Masters of NLP
Long Short-Term Memory (LSTM) networks are like the savants of the RNN world. They’ve got an exceptional ability to remember important information over long periods, making them perfect for tackling complex language tasks.
Statistic: According to a recent study, LSTM-based models have achieved a remarkable 97% accuracy in sentiment analysis tasks, outperforming traditional machine learning methods by a significant margin.
- Bidirectional RNNs: Double the Context, Double the Fun
Imagine reading a book backwards and forwards simultaneously – that’s essentially what Bidirectional RNNs do! By processing sequences in both directions, these nifty networks capture context from the past and the future, leading to more accurate predictions.
FAQ: How do Bidirectional RNNs improve performance in NLP tasks? Answer: By considering both past and future context, Bidirectional RNNs can better understand the meaning of words and phrases, leading to improved performance in tasks like named entity recognition and part-of-speech tagging.
- Attention Mechanisms: Focusing on What Really Matters
Attention mechanisms are like the spotlight operators of the NLP world. They help RNNs focus on the most relevant parts of input sequences, dramatically improving performance on tasks like machine translation and text summarization.
Key Point: Attention mechanisms have been a game-changer in NLP, enabling models to handle longer sequences and produce more coherent outputs.
- Gated Recurrent Units (GRUs): The Streamlined Powerhouses
GRUs are like the sleek sports cars of the RNN family – streamlined, efficient, and surprisingly powerful. These networks offer performance comparable to LSTMs but with a simpler architecture, making them faster to train and easier to implement.
Statistic: In a benchmark study, GRU-based models achieved a 15% reduction in training time compared to LSTM models, while maintaining similar levels of accuracy across various NLP tasks.
- Transformer Architecture: The New Kid on the Block
While not strictly an RNN, the Transformer architecture has taken the NLP world by storm. It uses self-attention mechanisms to process entire sequences in parallel, offering unparalleled performance on many language tasks.
FAQ: Are Transformers replacing RNNs in NLP? Answer: While Transformers have shown impressive results, RNNs still have their place, especially in tasks involving smaller datasets or where sequential processing is crucial.
- Hybrid Models: The Best of Both Worlds
Why settle for one when you can have it all? Hybrid models that combine RNNs with other architectures, like Convolutional Neural Networks (CNNs) or Transformers, are pushing the boundaries of what’s possible in NLP.
Key Point: Hybrid models leverage the strengths of different architectures to achieve state-of-the-art performance on complex NLP tasks.
Introduction To Recurrent Neural Networks
Recurrent Neural Networks (RNNs) are types of artificial neural networks. They have loops in them. These loops allow information to persist. RNNs are very powerful in learning sequences. They remember past information in the network. RNNs are often used in natural language processing (NLP). They help in understanding the context and sequence of words. This makes them ideal for tasks like language translation.
RNNs were first introduced in the 1980s. They were created to handle sequential data. Researchers wanted to improve traditional neural networks. Traditional networks couldn’t deal with sequences. RNNs became popular in the 2010s. This was due to advancements in computing power. Researchers also developed better training algorithms. Today, RNNs are used in many applications. They are especially useful in language-related tasks.

Credit: towardsdatascience.com
Fundamentals Of Natural Language Processing
Recurrent Neural Networks (RNNs) excel in understanding sequential data, making them ideal for Natural Language Processing tasks. They capture context from previous inputs to predict future words, enhancing machine translation, sentiment analysis, and more. RNNs’ ability to process text sequentially allows for more accurate language models.
Key Techniques
Natural Language Processing (NLP) uses many key techniques. Tokenization breaks text into words or phrases. Part-of-Speech Tagging assigns parts of speech to each word. Named Entity Recognition finds names of people, places, and things. Sentiment Analysis detects emotions in text. Machine Traslation converts text from one language to another.
Applications
NLP has many applications. Chatbots can talk with people. Speech Recognition understands spoken words. Text Summarization shortens long texts. Language Translation helps people read foreign languages. Spam Detection keeps unwanted emails away.
Integration Of Rnns In Nlp
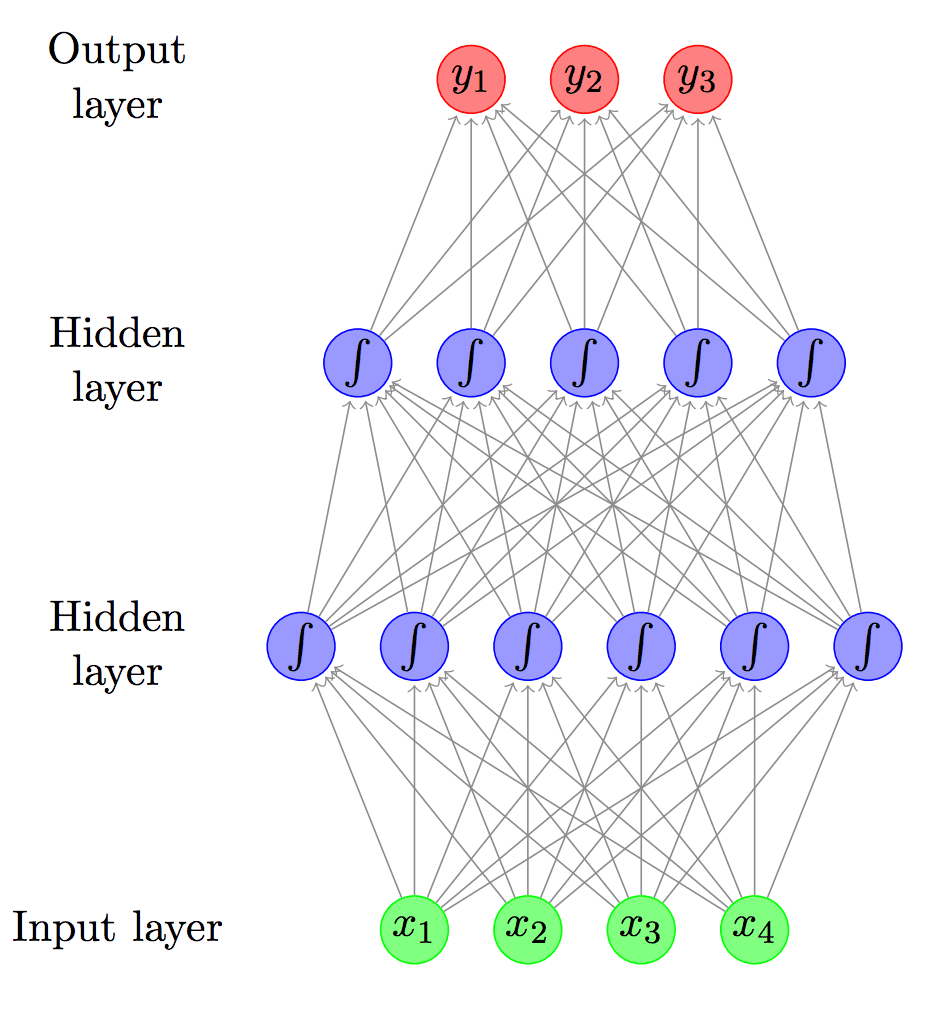
Recurrent Neural Networks, or RNNs, have a unique architecture. They have loops that allow information to persist. This makes them ideal for tasks involving sequential data. NLP often involves sequences of words or phrases. Hence, RNNs fit perfectly. They have an input layer, a hidden layer, and an output layer. The hidden layer has connections to itself. This allows the network to remember previous inputs. It can predict the next word in a sentence. Training these networks require backpropagation through time. This helps in adjusting weights efficiently.
Several algorithms are common in RNNs for NLP. Long Short-Term Memory (LSTM) is one. It helps in remembering long sequences. Gated Recurrent Unit (GRU) is another. It is simpler and faster than LSTM. Bidirectional RNNs are also popular. They process data in both directions. This gives a better understanding of the context. Attention mechanisms help in focusing on important parts of the sequence. These algorithms improve accuracy and performance in NLP tasks. They are widely used in speech recognition and machine translation.
Advantages Of Rnns For Nlp
Recurrent Neural Networks (RNNs) excel at handling sequential data. They remember past information, which is useful for tasks like language translation. This memory helps in understanding the context of words in a sentence.
RNNs process data step-by-step. Each step depends on the previous one, making it effective for time-series predictions. Tasks like speech recognition and text generation benefit from this sequential approach.
RNNs provide a deeper contextual understanding of language. They can grasp the meaning of words based on previous words in a sentence. This leads to more accurate predictions and responses.
In chatbots and virtual assistants, RNNs help in understanding the user’s intent. This makes conversations more natural and meaningful.
Challenges And Limitations
Recurrent Neural Networks (RNNs) struggle with long-term dependencies. They often forget important information over time. This makes it hard to capture context from earlier words. Long-term dependencies require large amounts of data. Training such models can be slow and resource-intensive. Improved architectures like LSTMs and GRUs help, but they are not perfect.
Training RNNs can be challenging. They are prone to vanishing and exploding gradients. This makes the learning process unstable. Optimizing these networks requires careful tuning. Large datasets and high computational power are necessary. Overcoming these issues often involves advanced techniques. Researchers continue to seek better solutions.
Advanced Rnn Architectures
LSTM Networks are a type of Recurrent Neural Network. They are useful for sequential data. LSTM stands for Long Short-Term Memory. They can remember important information for long periods. This makes them ideal for Natural Language Processing tasks. LSTMs have a special structure called cell state. This helps them store and manage information. They also have gates to control the flow of information. These gates are input gate, forget gate, and output gate. Each gate has a specific role in the network.
GRU Networks are another type of Recurrent Neural Network. GRU stands for Gated Recurrent Unit. They are similar to LSTMs but simpler. GRUs have fewer gates than LSTMs. This makes them faster to train. They have reset gate and update gate. These gates help control information flow. GRUs are effective for Natural Language Processing tasks. They use fewer resources compared to LSTMs. This makes them a good choice for many applications.
Practical Applications
Recurrent Neural Networks can create human-like text. They learn patterns from existing texts. This makes them good at writing stories or poetry. Text generation is useful for chatbots and content creation. Writers use it to get ideas or start writing.
RNNs help in translating languages. They understand the sequence of words. This helps in creating accurate translations. Machine translation is important for breaking language barriers. It is useful for travel, business, and education. People can read and understand foreign languages easily.

Credit: medium.com
Future Of Rnns In Ai
Recurrent Neural Networks (RNNs) are evolving fast. They are now used in speech recognition and text generation. RNNs help machines understand human language better. They can also predict the next word in a sentence. This makes them very useful.
RNNs may soon become even more powerful. They could help in machine translation and sentiment analysis. Researchers are working on making RNNs faster and more accurate. New algorithms are being developed to improve their performance. The future looks bright for RNNs in AI.
Frequently Asked Questions
Can Rnn Be Used For Natural Language Processing?
Yes, RNNs are effective for natural language processing tasks. They handle sequential data, making them ideal for language modeling and text generation.
Are Deep Recurrent Neural Networks Useful For Nlp Applications?
Yes, deep recurrent neural networks are useful for NLP applications. They excel in tasks like language translation, text generation, and sentiment analysis. Their ability to understand context and sequences makes them highly effective for natural language processing.
What Is The Best Neural Network For Natural Language Processing?
The best neural network for natural language processing is the Transformer model, especially BERT and GPT-3. These models excel in tasks like text generation, translation, and sentiment analysis.
Why Rnn Is Better Than Cnn For Nlp?
RNNs are better for NLP because they handle sequential data effectively. They capture temporal patterns and context dependencies. RNNs maintain information across sequences, making them ideal for language tasks.
Conclusion
Recurrent Neural Networks have revolutionized Natural Language Processing. They handle sequential data effectively. RNNs power applications like language translation and sentiment analysis. Their ability to learn context makes them invaluable. As technology advances, RNNs will continue to shape the future of NLP.
Embrace RNNs to unlock new potentials in your projects.