Master the art of NLP data preprocessing. Learn tokenization, stemming, and text normalization techniques. Improve your model accuracy and efficiency. Enhance your data science skills now!
NLP preprocessing transforms raw text into a structured format for analysis. Tokenization breaks text into meaningful units, while stop word removal eliminates common but insignificant words. Stemming and lemmatization reduce words to their base forms, enhancing consistency. These techniques improve the performance of machine learning models by reducing noise and ensuring relevant features.
Proper preprocessing is crucial for accurate sentiment analysis, topic modeling, and other NLP tasks. Implementing these methods ensures high-quality data, leading to reliable and actionable insights in data science projects. Effective NLP preprocessing is essential for extracting valuable information from text data.
Credit: www.explorium.ai
Introduction To Nlp Preprocessing
Natural Language Processing (NLP) transforms human language into data. Accurate data science results depend on high-quality text data. NLP preprocessing helps clean and prepare this text data.
Importance In Data Science
NLP preprocessing is crucial for data science. Clean data leads to more accurate models. Preprocessing removes noise and irrelevant information. This makes the data easier to analyze.
Consider an example. You have a dataset with many typos. NLP preprocessing corrects these errors. It standardizes the text. This improves the model’s performance.
Common Challenges
There are common challenges in NLP preprocessing. One challenge is handling different languages. Each language has unique rules and structures.
Another challenge is dealing with slang and abbreviations. People use informal language online. This can confuse NLP models. Preprocessing techniques help to standardize this language.
Finally, ambiguity in text is a major issue. Words can have multiple meanings. Context is key in understanding the correct meaning. NLP preprocessing techniques help in resolving this ambiguity.
| Challenge | Solution |
|---|---|
| Different Languages | Language-specific rules |
| Slang and Abbreviations | Standardization techniques |
| Ambiguity | Context analysis |
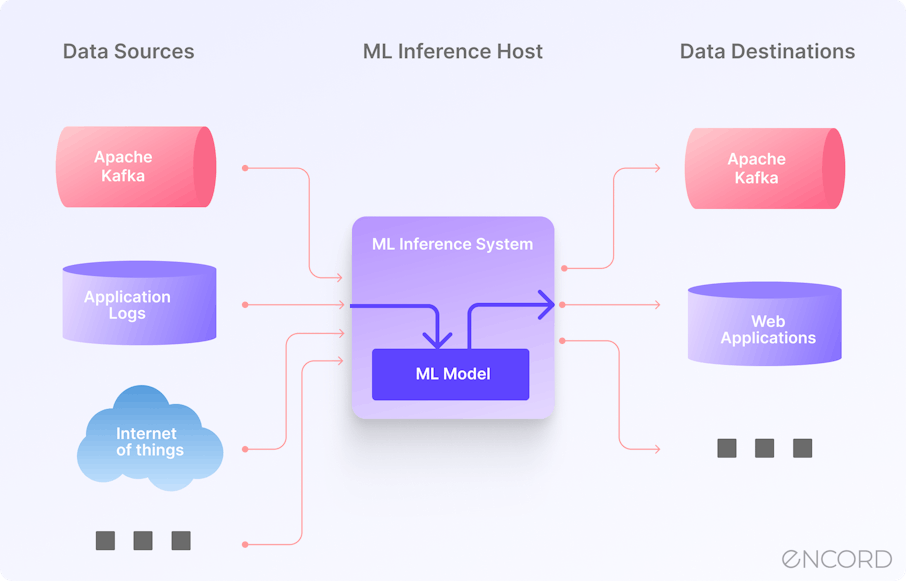
Credit: encord.com
Text Cleaning
Text cleaning is a crucial step in NLP preprocessing. It involves removing irrelevant data to improve analysis. Effective text cleaning ensures accurate and meaningful data science results.
Removing Noise
Noise refers to irrelevant or redundant data in text. This includes stop words, HTML tags, and special characters.
- Stop Words: Words like “and,” “the,” and “is” add no value.
- HTML Tags: Tags like
and
clutter the text.
- Special Characters: Symbols like @, #, and $ can confuse models.
Use libraries to remove noise. Python’s nltk and BeautifulSoup are effective tools.
Handling Punctuation
Punctuation marks need careful handling. They can affect text analysis and model performance.
- Removing Punctuation: This is useful for certain models. Use Python’s
string.punctuationto remove them. - Keeping Punctuation: Sometimes, punctuation conveys meaning. For example, “Let’s eat, Grandma” vs “Let’s eat Grandma.”
- Replacing Punctuation: Replace with spaces to maintain word boundaries.
Consider the context of your analysis. Choose the right approach based on your needs.
| Technique | Library/Tool | Example Code |
|---|---|---|
| Remove Noise | nltk, BeautifulSoup | from bs4 import BeautifulSoup; soup = BeautifulSoup(html, "html.parser"); clean_text = soup.get_text() |
| Remove Punctuation | string.punctuation | import string; text = text.translate(str.maketrans('', '', string.punctuation)) |
| Replace Punctuation | Regular Expressions (re) | import re; text = re.sub(r'[^\w\s]', ' ', text) |
Tokenization
Tokenization is a crucial step in NLP preprocessing. It involves splitting text into smaller units like words or sentences. This makes text easier to analyze and understand. Proper tokenization can improve the accuracy of data science models.
Word Tokenization
Word tokenization breaks down text into individual words. This helps in analyzing the meaning and context of each word. Tools like NLTK and SpaCy are popular for word tokenization.
Here’s an example of word tokenization using Python:
import nltk
nltk.download('punkt')
from nltk.tokenize import word_tokenize
text = "Tokenization is essential for NLP tasks."
tokens = word_tokenize(text)
print(tokens)
The output will be:
['Tokenization', 'is', 'essential', 'for', 'NLP', 'tasks', '.']
Sentence Tokenization
Sentence tokenization splits text into individual sentences. This helps in understanding the structure and flow of the text. Sentence tokenization is useful for tasks like summarization and translation.
Here is an example of sentence tokenization using Python:
from nltk.tokenize import sent_tokenize
text = "Tokenization is essential. It improves data science results."
sentences = sent_tokenize(text)
print(sentences)
The output will be:
['Tokenization is essential.', 'It improves data science results.']
Both word and sentence tokenization are foundational NLP preprocessing techniques. They help in breaking down text for better analysis and understanding.
Credit: www.mdpi.com
Stop Words Removal
Stop words are common words that add little value to text analysis. Words like “and”, “the”, and “is” are examples of stop words. Removing these words helps focus on meaningful content. This process is known as stop words removal.
Impact On Performance
Removing stop words can significantly improve model performance. It reduces the size of text data, making processing faster. Fewer words mean less noise in the data. This leads to more accurate models. Also, it helps in better feature extraction.
Here’s a simple example:
Original Text: "The cat sat on the mat."
Without Stop Words: "cat sat mat."
Notice the difference? The essential words stand out better. This helps in clearer text analysis.
Common Libraries
Several libraries offer stop words removal functionality. Some popular ones include:
- NLTK: Natural Language Toolkit (NLTK) is a popular library in Python. It comes with a built-in list of stop words.
- SpaCy: SpaCy is another powerful library. It provides efficient stop words removal and is optimized for performance.
- gensim: Gensim specializes in topic modeling and document similarity. It also includes a stop words list.
Here is a simple example using NLTK:
import nltk
from nltk.corpus import stopwords
nltk.download('stopwords')
example_text = "The quick brown fox jumps over the lazy dog."
stop_words = set(stopwords.words('english'))
words = example_text.split()
filtered_text = [word for word in words if word.lower() not in stop_words]
print(" ".join(filtered_text))
This code will output: “quick brown fox jumps lazy dog.”
As seen, removing stop words makes the text cleaner and more manageable.
Stemming And Lemmatization
Natural Language Processing (NLP) involves transforming text into an analyzable format. Two critical techniques in this process are Stemming and Lemmatization. These methods help in reducing words to their root forms, ensuring that variations of a word are analyzed as a single item. Understanding these techniques can significantly improve the accuracy of data science models.
Differences Between Them
Stemming and lemmatization, though similar, have unique differences:
| Aspect | Stemming | Lemmatization |
|---|---|---|
| Definition | Reduces words to their base form by removing suffixes. | Transforms words to their dictionary base form. |
| Output | May not always be a valid word. | Always returns a valid word. |
| Complexity | Simpler and faster. | More complex and slower. |
Use Cases
Stemming is ideal for applications needing speed and efficiency:
- Search Engines
- Spam Detection
- Information Retrieval Systems
Lemmatization is preferred in contexts requiring precision:
- Chatbots
- Machine Translation
- Text Summarization
For example, in a search engine, stemming helps in matching various forms of a word. Words like “running” and “runner” are reduced to “run”. This improves search results. In contrast, lemmatization is vital for chatbots to understand user queries accurately. It transforms words to their base form, ensuring precise responses.
Handling Special Characters
Special characters can complicate Natural Language Processing (NLP) tasks. They include emojis, symbols, and punctuation. Proper handling ensures accurate data science results.
Emojis And Symbols
Emojis and symbols are popular in social media and text messages. They carry emotions and meanings. Ignoring them can lead to data loss. Here’s how to handle them:
- Identify emojis and symbols using libraries like emoji and unicodedata.
- Convert them into meaningful text or remove them.
Example:
import emoji
text = "I love NLP! 😊"
text = emoji.demojize(text)
print(text) # Output: I love NLP! :smile:
Regular Expressions
Regular expressions (regex) offer a powerful way to handle special characters. They allow you to search, match, and manipulate text efficiently.
Common tasks include:
- Removing punctuation.
- Finding specific patterns.
- Replacing or extracting substrings.
Example:
import re
text = "Hello, world! NLP is fun. #DataScience"
# Remove punctuation
text = re.sub(r'[^\w\s]', '', text)
print(text) # Output: Hello world NLP is fun DataScience
Use regex to clean and preprocess text data. This ensures better data quality.
Text Normalization
Text normalization is a crucial step in Natural Language Processing (NLP). It transforms text into a standard format, ensuring consistency. This process enhances the accuracy of data analysis and model performance. Let’s dive into two essential text normalization techniques: Lowercasing and Expanding Contractions.
Lowercasing
Lowercasing is the process of converting all characters in a text to lowercase. This technique helps in standardizing text data.
Consider these sentences:
- Data Science is Amazing.
- data science is amazing.
Both sentences convey the same information but have different cases. Converting them to lowercase eliminates this discrepancy:
data science is amazing.This step reduces the complexity of text data. It ensures uniformity and simplifies further processing tasks.
Expanding Contractions
Expanding contractions is another vital text normalization technique. It involves replacing contractions with their full forms.
For instance, consider the contraction:
don'tExpanding it results in:
do notThis transformation enhances text clarity and improves the accuracy of NLP models. Below is a table of common contractions and their expansions:
| Contraction | Expansion |
|---|---|
| don’t | do not |
| can’t | cannot |
| I’m | I am |
| they’re | they are |
Expanding contractions ensures that all variations of words are treated equally. This results in more accurate data analysis.
Feature Extraction
Feature extraction is crucial in Natural Language Processing (NLP). It involves transforming text into numerical data. This allows algorithms to understand and process it. Two popular feature extraction methods are Bag of Words (BoW) and Term Frequency-Inverse Document Frequency (TF-IDF).
Bag Of Words
The Bag of Words (BoW) model is simple yet powerful. It converts text into a bag (or set) of words. Each word is a unique token. The number of times a word appears is counted. This count is then used to create a feature vector.
Here is an example:
| Document | Words | Feature Vector |
|---|---|---|
| Doc1 | apple, banana, apple | {apple: 2, banana: 1} |
| Doc2 | banana, orange, banana | {banana: 2, orange: 1} |
BoW is easy to implement and understand. But it has some limitations. It does not consider the order of words. It also does not capture context or meaning.
Tf-idf
Term Frequency-Inverse Document Frequency (TF-IDF) improves on BoW. It considers both the frequency of a word in a document and its importance across all documents. This helps in highlighting important words while reducing the weight of common words.
The formula for TF-IDF is:
TF-IDF = (Term Frequency) (Inverse Document Frequency)
Term Frequency (TF) is the number of times a word appears in a document. Inverse Document Frequency (IDF) is calculated as:
IDF = log(Total number of documents / Number of documents containing the term)
For example:
- Document1: “apple banana apple”
- Document2: “banana orange banana”
Let’s calculate TF-IDF for the term “apple” in Document1:
- TF(apple) = 2
- IDF(apple) = log(2/1) = 0.301
Thus, TF-IDF(apple) = 2 0.301 = 0.602.
TF-IDF provides better insights into the importance of words. It helps in improving the accuracy of models.
Frequently Asked Questions
What Are The 5 Major Steps Of Data Preprocessing?
The 5 major steps of data preprocessing are data cleaning, data integration, data transformation, data reduction, and data discretization. Data cleaning removes inconsistencies. Data integration combines data sources. Data transformation converts data formats. Data reduction simplifies datasets. Data discretization segments data into intervals.
What Are The Steps Involved In Preprocessing Data For Nlp?
Preprocessing data for NLP involves several steps. First, clean the text by removing punctuation. Second, convert text to lowercase. Third, tokenize the text into words. Fourth, remove stop words. Fifth, lemmatize or stem the words. These steps ensure clean, structured data for NLP tasks.
What Are The Six Techniques Used For Data Preprocessing?
The six techniques for data preprocessing are: data cleaning, data integration, data transformation, data reduction, data discretization, and data normalization. These methods enhance data quality and prepare it for analysis.
How Is Nlp Used In Data Science?
NLP in data science processes and analyzes natural language data. It helps in sentiment analysis, text classification, and language translation, enhancing data insights.
Conclusion
Mastering NLP preprocessing techniques is crucial for precise data science results. Clean, structured data leads to better insights. Apply these methods to enhance your data analysis. Accurate preprocessing ensures reliable outcomes and boosts your project’s success. Keep refining your skills to stay ahead in the data science field.