

Decision Tree Machine Learning involves using a model that splits data into branches to make decisions. It is highly interpretable and widely used in various applications.
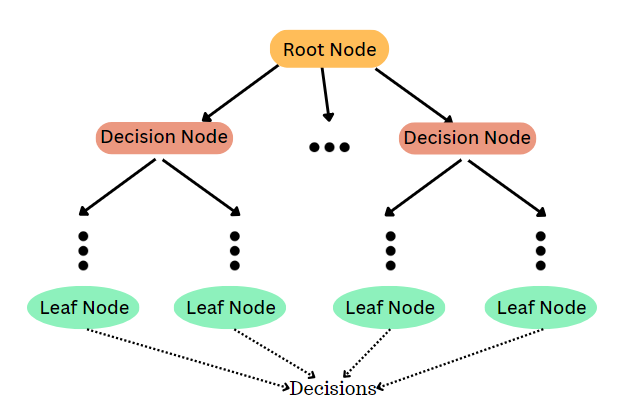
Decision Trees are a popular machine learning method due to their simplicity and interpretability. They work by recursively splitting data into subsets based on certain criteria, forming a tree-like structure. Each node represents a decision point, and each branch represents an outcome.
These trees can handle both numerical and categorical data and are useful for classification and regression tasks. Decision Trees are easy to visualize, making them ideal for understanding data patterns and decision-making processes. Their ability to handle complex datasets with minimal preprocessing makes them a versatile tool in the machine learning toolkit.
Introduction To Decision Trees In Machine Learning
Decision Trees are simple yet powerful tools. They help in making decisions based on data. Each branch of the tree represents a choice. Each leaf represents an outcome. They are used in both classification and regression tasks.
Understanding the structure is easy. This makes them popular in many fields. They help in solving real-world problems. Their visual nature aids in comprehension.
Decision Trees play a crucial role in modern analytics. They help to uncover patterns in data. Their predictive power is significant. Businesses use them to make informed decisions.
They offer clear insights. This is especially useful in data mining. They are also used in risk management. Their simplicity does not reduce their effectiveness.
Key Concepts Behind Decision Trees
Decision trees use different rules to split data. The two main rules are Gini and Entropy. Gini measures how often a randomly chosen element would be incorrectly identified. Entropy measures the level of disorder or impurity. Both help the tree decide the best way to split data. Gini is easier to compute, while Entropy can be more precise.
Tree depth refers to how many levels a decision tree has. A deeper tree can capture more details. But, it can also lead to overfitting. Overfitting means the tree works well on training data but fails on new data. Keeping the tree depth balanced is important. A balanced tree performs well on both training and new data.
Types Of Decision Trees
Classification trees help in categorizing data. They split data into groups. Each group has a label. Labels can be like “yes” or “no”. These trees are useful for tasks like spam detection. They make decisions based on attributes.
Regression trees predict numerical values. They are used for continuous data. For example, predicting house prices. They split data into ranges. Each range has a value. Values can be like 100 or 200. These trees are good for forecasting tasks.

Credit: m.youtube.com
Building A Decision Tree: Step-by-step
Start with cleaning your data. Remove any missing values or outliers. Normalize the data if needed. Split the data into training and test sets. This helps in evaluating the model later. Label encoding is important for categorical variables. It transforms them into numerical values.
A decision tree uses nodes and branches. Each node represents a feature. Each branch represents a decision. The goal is to reach a leaf node. Leaf nodes represent the final decision. The tree is built using a recursive algorithm. Splitting criteria like Gini Index or Entropy are used.
Pruning helps in avoiding overfitting. It removes unnecessary branches. Pre-pruning stops the tree from growing too large. Post-pruning removes branches after the tree is built. Both methods help in keeping the model simple and efficient.
Evaluating Model Performance
A confusion matrix helps check model performance. It shows true positives, true negatives, false positives, and false negatives. True positives are correctly predicted positive values. True negatives are correctly predicted negative values. False positives are incorrect positive predictions. False negatives are incorrect negative predictions. By analyzing the confusion matrix, we can get insights into the model’s accuracy and errors.
Cross-validation is a method to check the model’s performance. It helps avoid overfitting and underfitting. One common technique is k-fold cross-validation. Here, data is split into k parts. The model is trained k times, each time using a different part for testing. Another method is leave-one-out cross-validation. Each data point is used once for testing. Both techniques help ensure the model works well on new data.
Advantages Of Using Decision Trees
Decision trees are easy to understand. Each decision is clear and simple. The tree structure makes it easy to follow. Users can see the entire process. This helps in explaining the model to others. Even non-experts can understand the decisions. Visualization tools make trees even clearer. Graphs and charts can show the tree. This makes it easy to spot patterns. Interpretability is a key benefit of decision trees.
Decision trees can handle complex data. Non-linear relationships are not a problem. Each node splits data into smaller parts. This helps in capturing complex patterns. The tree can adapt to different shapes of data. Non-linear data fits well with decision trees. Flexibility is another strength of these models. They work well with many types of data.
Challenges And Limitations
Decision trees are very sensitive to noise in the data. Small errors can cause big changes in the tree’s structure. This makes the model unstable. Noise can lead to overfitting, where the tree fits the noise instead of the signal. Overfitting reduces the model’s accuracy on new data. Pruning methods can help to reduce the impact of noise.
Small changes in the data can lead to completely different decision trees. This makes the model unreliable. Decision trees can split the data in many ways. Even a small variation can change the splits. This can make it hard to understand the model. Ensuring consistent splits is crucial for reliability.
Credit: towardsdatascience.com
Real-world Applications
Decision trees help in credit scoring. They can predict if a loan will default. Banks use them to detect fraud. They help in choosing the best investment options. Easy to understand, they assist in risk management. They analyze customer behavior to improve services.
Doctors use decision trees to diagnose diseases. They help in predicting patient outcomes. They assist in choosing the best treatment plans. They can analyze medical data quickly. They help in identifying high-risk patients. They make healthcare more efficient and accurate.
Advanced Decision Tree Algorithms
Random Forests use many decision trees. Each tree gets a random set of data. The forest combines all trees to make a decision. This method reduces errors. It works well with large datasets. Random Forests are popular in many fields. These include finance and healthcare.
Boosted Trees improve decision trees. They create new trees to correct errors from previous trees. Each new tree focuses on mistakes of the last. Boosted Trees are strong against overfitting. They work well with small datasets. They are often used in competitions. XGBoost is a popular boosting algorithm.
Credit: medium.com
Practical Tips For Implementation
Use important features to build stronger trees. Focus on features that impact the outcome the most. You can use feature selection techniques to find these features. This will help in simplifying the model. It will also make the model more accurate.
Avoid overfitting by using techniques like pruning. Overfitting makes the model perform poorly on new data. Also, balance your data to avoid biased results. Unbalanced data can mislead the model. Use cross-validation to ensure the model works well. Cross-validation helps in testing the model on different data sets. Always check for errors in your data. Clean data helps the model to learn better.
The Future Of Decision Trees
Decision trees can be combined with neural networks. This can create more powerful models. Ensemble methods like random forests use many decision trees. This makes predictions more accurate. Hybrid models mix decision trees with other algorithms. They can solve complex problems better. AI integration is key for future growth.
Algorithms for decision trees keep improving. New techniques make trees grow faster. This helps handle big data more easily. Pruning methods remove unneeded parts of the tree. This makes models simpler and faster. Practices evolve as researchers find better ways to use trees. Continuous updates ensure models stay efficient.
Frequently Asked Questions
When To Use Decision Trees In Machine Learning?
Use decision trees when you need simple, interpretable models. They handle both classification and regression tasks. Ideal for non-linear relationships, missing values, and mixed data types. Great for visualizing decision paths.
What Is The Id3 Algorithm In Ml?
The ID3 algorithm in ML is a decision tree algorithm. It uses entropy and information gain to split data. This method helps in creating a tree that classifies data efficiently. ID3 is mainly used for classification tasks.
What Is The Difference Between A Decision Tree And A Random Forest?
A decision tree is a single tree model for decision making. A random forest combines multiple trees to improve accuracy and reduce overfitting.
Is Xgboost A Decision Tree?
No, XGBoost is not a decision tree. It is an ensemble learning method that uses multiple decision trees for predictions.
Conclusion
Decision trees offer a powerful way to make data-driven decisions. They are easy to understand and implement. By mastering this technique, you can unlock valuable insights from complex datasets. Start exploring decision trees today to enhance your machine learning projects.