Unlock the power of machine learning in NLP for data science. Learn about SVM, Naive Bayes, and deep learning techniques. Enhance your ML skills and tackle complex NLP challenges. Start learning now!
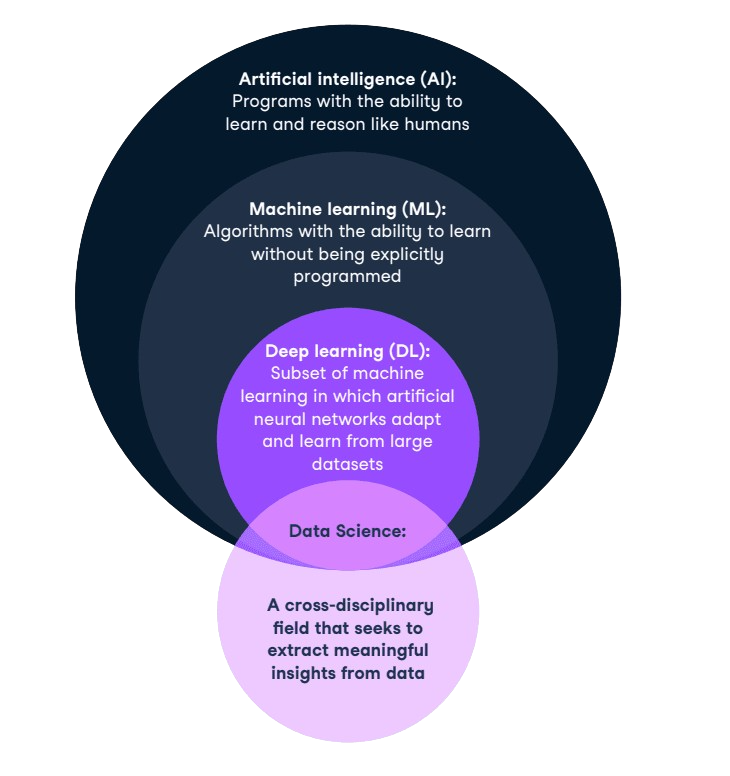
Natural Language Processing (NLP) transforms human language into a format that computers can understand. Machine learning algorithms play a crucial role in this process by enabling systems to learn from data and improve over time. Decision trees help in classification tasks, while support vector machines are effective in text categorization.
Neural networks, especially deep learning models, excel in complex tasks such as language translation and sentiment analysis. Mastering these algorithms enhances your ability to create sophisticated NLP applications, driving advancements in fields like customer service, healthcare, and e-commerce. Understanding these tools is essential for anyone looking to delve into data science and NLP.
Tokenization Techniques
Tokenization is the first step in many Natural Language Processing (NLP) tasks. It involves breaking down text into smaller units called tokens. These tokens can be words, subwords, or characters. Tokenization helps in understanding text and its structure. Let’s dive into different tokenization techniques.
Word Tokenization
Word tokenization splits text into individual words. Each word is a token. This technique is simple and effective for many languages.
Example:
Text: "Machine learning is fun." Tokens: ["Machine", "learning", "is", "fun"]
Word tokenization works well for languages with clear word boundaries. It struggles with languages without spaces between words, like Chinese or Japanese. It also may not handle contractions or compound words well.
Subword Tokenization
Subword tokenization breaks text into subword units. It helps in dealing with unknown words and rare words.
Example:
Text: "unhappiness" Tokens: ["un", "happiness"]
There are several methods for subword tokenization:
- Byte Pair Encoding (BPE): Repeatedly merges frequent pairs of characters or subwords.
- WordPiece: Used by BERT, it splits words into smaller units based on frequency.
- SentencePiece: Developed by Google, it treats the input as a sequence of characters and learns the best split.
Subword tokenization is useful for handling diverse vocabularies. It is especially effective for morphologically rich languages.
| Method | Usage |
|---|---|
| BPE | OpenAI GPT |
| WordPiece | BERT |
| SentencePiece | T5 |
Tokenization is crucial for NLP tasks. Choosing the right technique depends on the language and the specific use case.
Credit: www.datacamp.com
Text Preprocessing
Text preprocessing is the initial and crucial step in Natural Language Processing (NLP). It transforms raw text into a clean and structured format. This process ensures machine learning algorithms understand and process the data effectively. Let’s dive into some essential text preprocessing techniques.
Stop Words Removal
Stop words are common words that carry little useful information. Words like “and”, “the”, “is”, and “in” are examples. Removing them helps reduce noise in the data.
- Efficiency: Improves computation speed and memory usage.
- Relevance: Focuses on meaningful words in the text.
Here’s a simple example in Python:
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
filtered_sentence = [w for w in word_tokens if not w in stop_words]Stemming And Lemmatization
Stemming and lemmatization reduce words to their root forms. This helps in understanding the core meaning of words.
Stemming
Stemming cuts off the end of words. It often results in non-words but helps in reducing the total number of terms. For example, “running” becomes “run”.
Example code:
from nltk.stem import PorterStemmer
ps = PorterStemmer()
stemmed_words = [ps.stem(w) for w in word_tokens]Lemmatization
Lemmatization considers the context and converts words to their base form. It provides proper dictionary words. For example, “better” becomes “good”.
Example code:
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatized_words = [lemmatizer.lemmatize(w) for w in word_tokens]Both techniques help in improving the performance of NLP models.
Bag Of Words
The Bag of Words model is a simple and powerful tool in NLP. It transforms text into numerical features. This is useful for machine learning algorithms. Let’s dive into the key aspects of Bag of Words.
Vector Representation
The first step in Bag of Words is tokenization. This means splitting text into individual words or tokens. Each unique token forms a part of our vocabulary.
Next, we create a vector for each document. This vector records the frequency of each word. For example, consider the sentences below:
| Sentence | Tokenized | Vector |
|---|---|---|
| Dog bites man | [‘Dog’, ‘bites’, ‘man’] | [1, 1, 1, 0] |
| Man bites dog | [‘Man’, ‘bites’, ‘dog’] | [1, 1, 1, 0] |
| Dog eats food | [‘Dog’, ‘eats’, ‘food’] | [1, 0, 1, 1] |
The vector shows word presence and frequency. Words not in the sentence get a zero.
Applications
Bag of Words is used in many NLP applications. Here are some examples:
- Text Classification: Categorizing emails as spam or not.
- Sentiment Analysis: Determining if a review is positive or negative.
- Topic Modeling: Finding the main topics in a set of documents.
The simplicity of Bag of Words makes it a go-to model for many NLP tasks. It is easy to understand and implement.
Tf-idf
In the realm of Natural Language Processing (NLP), understanding the importance of words within documents is crucial. One of the key techniques used to achieve this is TF-IDF (Term Frequency-Inverse Document Frequency). This method helps quantify the importance of a word in a document relative to a collection of documents (corpus). Let’s delve into the components of TF-IDF.
Term Frequency
Term Frequency (TF) measures how frequently a term appears in a document. It helps in understanding the relevance of a word within a single document. The formula for calculating TF is:
TF = (Number of times term t appears in a document) / (Total number of terms in the document)For instance, if the word “data” appears 3 times in a document with 100 words, the TF for “data” is 0.03.
Inverse Document Frequency
Inverse Document Frequency (IDF) helps determine how important a word is across multiple documents. It balances out the term frequency by giving less importance to common words. The formula for calculating IDF is:
IDF = log_e(Total number of documents / Number of documents with term t in it)For example, if the word “science” appears in 10 out of 1000 documents, the IDF for “science” is:
IDF = log_e(1000 / 10) = log_e(100) ≈ 4.605Combining TF and IDF gives a comprehensive measure of the importance of a word in a document relative to a corpus.
Word Embeddings
Word embeddings capture the semantic meaning of words in numerical form, enhancing NLP models’ accuracy and performance. Essential for text analysis, these algorithms transform text data into meaningful vectors. Optimize your data science projects with these powerful tools for efficient natural language processing.
Word embeddings are a crucial concept in Natural Language Processing (NLP). They transform words into numerical vectors. This allows algorithms to understand text. These vectors capture semantic meanings. This makes them essential for many NLP tasks.
Word2vec
Word2Vec is a popular word embedding technique. Developed by Google, it uses neural networks. There are two main models: Continuous Bag of Words (CBOW) and Skip-gram.
- CBOW: Predicts a word based on its context.
- Skip-gram: Predicts the context from a word.
Word2Vec captures relationships between words. For example, it understands that “king” and “queen” are related.
Here is a simple example of Word2Vec in Python:
from gensim.models import Word2Vec
# Sample sentences
sentences = [['cat', 'say', 'meow'], ['dog', 'say', 'woof']]
# Train the model
model = Word2Vec(sentences, min_count=1)
# Get word vectors
vector = model.wv['cat']
print(vector)
Glove
GloVe, short for Global Vectors, is another word embedding technique. Developed by Stanford, GloVe uses word co-occurrence statistics. This captures global context in a corpus.
GloVe creates word vectors by factorizing a word co-occurrence matrix. This makes it different from Word2Vec.
Here is a simple example of GloVe in Python:
import numpy as np
# Sample co-occurrence matrix
co_occurrence_matrix = np.array([[1, 2], [3, 4]])
# Factorize the matrix to get word vectors
U, S, V = np.linalg.svd(co_occurrence_matrix)
word_vectors = U @ np.sqrt(np.diag(S))
print(word_vectors)
Word embeddings like Word2Vec and GloVe are foundational in NLP. They power many applications, from chatbots to translation services.

Credit: medium.com
Recurrent Neural Networks
Recurrent Neural Networks (RNNs) are a class of neural networks. They are effective for sequential data. RNNs are vital for tasks involving text, speech, and time series. The structure of RNNs allows them to maintain a memory. This is crucial for understanding context in sequences.
Lstm
Long Short-Term Memory (LSTM) networks are a type of RNN. They are designed to remember long-term dependencies. LSTMs have a special architecture. This architecture helps them learn what to remember and what to forget.
| Feature | Description |
|---|---|
| Cell State | Stores long-term information. |
| Forget Gate | Decides what information to discard. |
| Input Gate | Decides what new information to store. |
| Output Gate | Decides what information to output. |
LSTMs are powerful for tasks like language modeling. They excel in applications like text generation and translation.
Gru
Gated Recurrent Unit (GRU) is another type of RNN. GRUs are simpler than LSTMs. They have fewer gates and are easier to train. Despite their simplicity, GRUs perform well for many tasks.
- Update Gate: Combines the forget and input gates of LSTM.
- Reset Gate: Helps decide how much past information to forget.
GRUs are efficient for real-time applications. They are suitable for tasks like speech recognition and sentiment analysis.
Both LSTMs and GRUs enhance the capabilities of RNNs. They enable better handling of long-term dependencies. Choosing between LSTM and GRU depends on the specific task and computational resources.
Transformers
Transformers have revolutionized the field of Natural Language Processing (NLP). These algorithms handle various NLP tasks with impressive accuracy. Unlike traditional models, transformers leverage a unique architecture that captures context more effectively. This section delves into key components like the Attention Mechanism, and popular models such as BERT and GPT.
Attention Mechanism
The Attention Mechanism is crucial for transformers. It allows the model to focus on relevant parts of the input. Traditional models struggle to capture long-range dependencies. The attention mechanism resolves this by weighing the importance of different words. Each word gets a score based on its relevance. Higher scores mean more focus during processing.
For example, in a sentence, “The cat sat on the mat,” attention helps identify “cat” and “sat” as key words. This helps the model understand the sentence better. Attention mechanism ensures better context understanding. This leads to more accurate predictions and translations.
Bert And Gpt
BERT stands for Bidirectional Encoder Representations from Transformers. It reads text in both directions. This bidirectional approach captures context from both ends. BERT excels in tasks like question answering and sentiment analysis. It can understand the full meaning of a word based on its surroundings.
GPT, or Generative Pre-trained Transformer, is another popular model. GPT focuses on generating coherent text. It predicts the next word in a sentence. GPT is excellent for creative tasks like story writing. It can generate human-like text with impressive accuracy.
Here’s a quick comparison of BERT and GPT:
| Feature | BERT | GPT |
|---|---|---|
| Reading Direction | Bidirectional | Unidirectional |
| Main Use | Understanding text | Generating text |
| Strength | Contextual understanding | Text generation |
Both BERT and GPT have their strengths. BERT is great for understanding. GPT excels at generating. Together, they form the backbone of modern NLP.

Credit: www.cloudfactory.com
Evaluation Metrics
To measure the performance of NLP algorithms, we use evaluation metrics. These metrics help us understand the effectiveness of our models. Key metrics include Precision, Recall, and the F1 Score.
Precision And Recall
Precision measures the accuracy of positive predictions. It is the ratio of correctly predicted positive observations to the total predicted positives.
For example, if a model predicts 10 spam emails, and 8 are actually spam, the Precision is 80%.
Recall is the ability of a model to find all relevant cases within a dataset. It is the ratio of correctly predicted positive observations to all observations in the actual class.
For instance, if there are 20 spam emails, and the model correctly identifies 15, the Recall is 75%.
| Metric | Formula |
|---|---|
| Precision | True Positives / (True Positives + False Positives) |
| Recall | True Positives / (True Positives + False Negatives) |
F1 Score
The F1 Score is a weighted average of Precision and Recall. It combines both metrics to give a single performance score.
The F1 Score is useful when you need a balance between Precision and Recall.
It is calculated as follows:
F1 Score = 2 (Precision Recall) / (Precision + Recall)For example, if Precision is 0.8 and Recall is 0.75, the F1 Score is 0.77.
Use the F1 Score to evaluate models with uneven class distributions.
Future Trends In Nlp
The field of Natural Language Processing (NLP) is evolving rapidly. New technologies and ethical considerations are shaping its future. This guide explores the trends that will dominate NLP.
Ethical Considerations
Ethics in NLP is gaining importance. Ensuring fairness and transparency is critical. There are several key areas to focus on:
- Bias Mitigation: Reducing bias in language models is crucial. Biased models can lead to unfair outcomes.
- Data Privacy: Protecting user data is paramount. Secure data handling practices are essential.
- Transparency: Models should be explainable. Users must understand how decisions are made.
Emerging Technologies
Several emerging technologies are transforming NLP:
| Technology | Description |
|---|---|
| Transformers | Transformers are revolutionizing NLP. They provide better context understanding. |
| Zero-Shot Learning | This technique enables models to understand tasks without direct training. |
| Reinforcement Learning | It helps models learn from interactions. It improves decision-making capabilities. |
These technologies promise a brighter future for NLP. They make NLP models more efficient and effective.
Frequently Asked Questions
Which Machine Learning Algorithm Is Best For Nlp?
The best machine learning algorithm for NLP is the Transformer model, especially BERT and GPT. These models excel in understanding and generating human language.
What Are The 4 Types Of Machine Learning Algorithms?
The four types of machine learning algorithms are supervised learning, unsupervised learning, semi-supervised learning, and reinforcement learning. Each type has distinct applications and methods. Supervised learning uses labeled data. Unsupervised learning works with unlabeled data. Semi-supervised learning combines both. Reinforcement learning relies on rewards and punishments.
What Are The Models And Algorithms That Can Be Used For Nlp?
Popular NLP models include BERT, GPT-3, and Transformer. Algorithms like Naive Bayes, Hidden Markov Models, and LSTM are also widely used.
What Is The A Algorithm In Nlp?
The A* algorithm in NLP is a pathfinding and graph traversal technique. It finds the shortest path between nodes. It’s widely used in machine translation and text generation.
Conclusion
Mastering these essential machine learning algorithms is crucial for NLP success. They empower data scientists to tackle complex language tasks efficiently. Keep exploring and experimenting to stay ahead in this dynamic field. Understanding these algorithms will boost your NLP projects and drive impactful results.
Stay curious and keep learning!