

Image segmentation using deep learning involves partitioning an image into meaningful regions. This technique enhances image analysis accuracy in various applications.
Image segmentation is a crucial aspect of computer vision, enabling machines to understand and interpret visual data. Deep learning techniques, particularly convolutional neural networks (CNNs), have revolutionized this field. These networks learn hierarchical features from raw image data, allowing precise segmentation.
Applications range from medical imaging and autonomous vehicles to facial recognition and augmented reality. The use of deep learning ensures high accuracy and efficiency in segmenting complex images. By leveraging vast datasets and powerful algorithms, image segmentation has become more robust, paving the way for advancements in artificial intelligence and machine learning.
Introduction To Image Segmentation
Image segmentation is a crucial technique in the field of computer vision. It divides an image into distinct regions or segments. Each segment represents a specific object or part of the image. This technique is essential for understanding the content of images at a pixel level. Using deep learning, image segmentation has become more accurate and efficient.
Importance In Ai
Image segmentation plays a vital role in artificial intelligence. It enhances the accuracy of object detection and recognition tasks. By isolating objects in images, AI models can better understand scenes. This leads to improved decision-making processes. Deep learning models, such as Convolutional Neural Networks (CNNs), are often used for this purpose.
Real-world Applications
Image segmentation has numerous real-world applications:
- Medical Imaging: Helps in detecting tumors and abnormalities.
- Autonomous Vehicles: Identifies road signs, pedestrians, and obstacles.
- Satellite Imagery: Assists in land use and environmental monitoring.
- Facial Recognition: Enhances security and authentication systems.
Below is a table summarizing the applications:
| Application | Description |
|---|---|
| Medical Imaging | Detects tumors and other abnormalities in scans. |
| Autonomous Vehicles | Identifies road signs, pedestrians, and obstacles. |
| Satellite Imagery | Monitors land use and environmental changes. |
| Facial Recognition | Improves security and authentication processes. |
Deep Learning Basics
Deep learning has revolutionized the field of image segmentation. It uses neural networks to understand and segment images. This section will cover the basics of deep learning and its key concepts.
Neural Networks
Neural networks are the backbone of deep learning. They consist of layers of nodes that process input data. These nodes are also called neurons.
Each neuron performs a simple computation. The results are passed to the next layer. This process continues until the final output is produced.
Neural networks can learn from data. They adjust their weights based on errors. This learning process is called training.
Here are the main components of a neural network:
- Input Layer: The first layer that receives data.
- Hidden Layers: Intermediate layers that process data.
- Output Layer: The final layer that produces the result.
Key Concepts
Understanding key concepts is essential in deep learning. Here are a few important ones:
Activation Functions: These functions decide if a neuron should be activated. Common examples include ReLU and Sigmoid.
Loss Function: This measures the difference between the predicted output and the actual output. The goal is to minimize this loss.
Backpropagation: This is the process of updating weights. It helps in minimizing the loss function.
Epochs: One epoch means one complete pass through the training dataset. Multiple epochs improve the learning process.
| Concept | Description |
|---|---|
| Activation Functions | Decide neuron activation |
| Loss Function | Measures prediction error |
| Backpropagation | Updates weights to minimize loss |
| Epochs | Complete passes through the data |
These key concepts are critical for understanding deep learning. They help in building effective neural networks for image segmentation.
Types Of Image Segmentation
Image segmentation is a crucial task in computer vision. It divides an image into meaningful segments. This is essential for various applications, from medical imaging to autonomous driving. There are two main types of image segmentation: Semantic Segmentation and Instance Segmentation.
Semantic Segmentation
Semantic Segmentation classifies each pixel in an image. The goal is to label every pixel with a category. For example, in a street scene, it labels pixels as road, car, or pedestrian. This type of segmentation does not differentiate between instances of the same class.
Here is a simple example:
| Pixel | Label |
|---|---|
| 1 | Road |
| 2 | Car |
| 3 | Pedestrian |
In this example, all pixels labeled “Car” belong to the same class. This method is useful for applications where the exact instance is not important.
Instance Segmentation
Instance Segmentation goes a step further. It not only classifies pixels but also differentiates between instances of the same class. This is essential for tasks that require precise localization of objects.
For example:
- Each car in a street scene is labeled separately.
- Each person in a crowd is identified uniquely.
Instance Segmentation provides detailed information about the objects in an image. This is crucial for applications like autonomous vehicles and robotics. It enables systems to understand their environment better.
Here is a comparison between the two types:
| Feature | Semantic Segmentation | Instance Segmentation |
|---|---|---|
| Pixel Classification | Yes | Yes |
| Instance Differentiation | No | Yes |
| Use Case | General Image Labeling | Precise Object Localization |
Both types of segmentation are vital. They serve different purposes in the field of image analysis. Understanding their differences helps in choosing the right approach for a given task.

Credit: www.v7labs.com
Popular Deep Learning Models
Image segmentation is a crucial task in computer vision. Deep learning models have revolutionized this field. Various popular models are frequently used for image segmentation tasks. These models provide accurate and efficient results.
Convolutional Neural Networks
Convolutional Neural Networks (CNNs) are fundamental in deep learning for image segmentation. CNNs use layers to extract features from images. They consist of convolutional layers, pooling layers, and fully connected layers.
The convolutional layers use filters to detect different features. Pooling layers reduce the dimensionality of the data. Fully connected layers classify the segmented parts. CNNs are powerful in recognizing patterns and structures in images.
U-net Architecture
The U-Net architecture is specifically designed for image segmentation tasks. It consists of an encoder and a decoder. The encoder compresses the input image into feature maps. The decoder reconstructs the segmented output from these feature maps.
U-Net uses skip connections to merge features from the encoder to the decoder. This helps preserve spatial information. U-Net is highly effective in medical imaging and other applications. It provides precise and detailed segmentation results.
| Model | Components | Applications |
|---|---|---|
| Convolutional Neural Networks | Convolutional Layers, Pooling Layers, Fully Connected Layers | General Image Segmentation |
| U-Net Architecture | Encoder, Decoder, Skip Connections | Medical Imaging, Detailed Segmentation |
Training Data And Annotation
Image segmentation is a critical task in computer vision. It involves partitioning an image into multiple segments to simplify its analysis. Training data and annotation play pivotal roles in the success of deep learning models for image segmentation. This section will discuss the essentials of data collection and annotation techniques.
Data Collection
Collecting high-quality training data is crucial for accurate image segmentation. Data should represent various scenarios to ensure the model’s robustness. The sources for data collection can include:
- Public datasets
- Custom image captures
- Data augmentation techniques
Public datasets provide a vast array of pre-annotated images. They are beneficial for benchmarking and initial training. Examples include MS COCO, PASCAL VOC, and Cityscapes. For specific use cases, custom image captures may be necessary. Use high-resolution cameras to capture diverse scenes.
Data augmentation enhances the diversity of the training dataset. Techniques like rotation, flipping, and scaling can simulate different conditions.
Annotation Techniques
Annotation converts raw images into valuable training data. Accurate annotation is vital for model performance. There are several techniques to annotate images:
- Manual Annotation
- Semi-Automatic Annotation
- Automatic Annotation
Manual annotation involves human annotators drawing boundaries around objects. It is time-consuming but ensures high accuracy. Use tools like Labelbox or RectLabel to facilitate the process.
Semi-automatic annotation combines human effort with AI tools. Annotators correct AI-generated labels. This method speeds up the process while maintaining accuracy. Tools like DeepLabCut aid in semi-automatic annotation.
Automatic annotation uses pre-trained models to label images. It is fast but may lack precision. Fine-tuning these models on specific datasets can improve results.
The table below summarizes the advantages and disadvantages of each annotation technique:
| Annotation Technique | Advantages | Disadvantages |
|---|---|---|
| Manual Annotation | High accuracy | Time-consuming |
| Semi-Automatic Annotation | Balanced accuracy and speed | Requires human correction |
| Automatic Annotation | Fast | May lack precision |

Credit: indiaai.gov.in
Challenges And Solutions
Image segmentation using deep learning faces various challenges. Solutions to these challenges improve the segmentation process. This section discusses these challenges and solutions.
Computational Costs
Deep learning models require powerful hardware. Training these models involves high computational costs. GPUs and TPUs are necessary for faster processing. These devices are expensive and consume much power.
To reduce costs, optimize code and algorithms. Use cloud computing services. These services offer scalable and cost-effective solutions. Prune models to remove unnecessary parameters. This reduces memory and computation requirements.
Another solution is model quantization. This process reduces the model size. It also improves inference speed. Use techniques like knowledge distillation. This trains smaller models to mimic larger ones.
Accuracy Improvements
Improving accuracy is crucial for image segmentation. High accuracy ensures better results. Use advanced architectures like U-Net or Mask R-CNN. These models have shown high performance in image segmentation tasks.
Data augmentation is another technique. It increases the diversity of training data. This improves model accuracy. Techniques include rotation, flipping, and scaling images.
Implementing transfer learning also boosts accuracy. Use pre-trained models on large datasets. Fine-tune these models for specific tasks. This approach saves time and resources.
Ensemble methods combine multiple models. This leads to improved accuracy. Use techniques like bagging and boosting. These methods reduce errors and enhance performance.
| Challenge | Solution |
|---|---|
| High Computational Costs | Optimize code, use cloud services, prune models, model quantization |
| Accuracy Improvements | Advanced architectures, data augmentation, transfer learning, ensemble methods |
These solutions address the challenges of image segmentation using deep learning. Implementing these solutions enhances performance and efficiency.
Evaluation Metrics
When using deep learning for image segmentation, evaluating the model’s performance is crucial. Evaluation metrics help us understand how well our model is doing. Let’s explore some of the key metrics.
Precision And Recall
Precision and Recall are fundamental metrics in any classification task. In image segmentation, these metrics measure how well the model identifies the correct segments.
Precision is the ratio of correctly predicted positive observations to the total predicted positives. The formula for precision is:
Precision = True Positives / (True Positives + False Positives)
Recall is the ratio of correctly predicted positive observations to the all observations in actual class. The formula for recall is:
Recall = True Positives / (True Positives + False Negatives)
To better understand these metrics, let’s consider the following table:
| Metric | Formula | Interpretation |
|---|---|---|
| Precision | TP / (TP + FP) | How many selected items are relevant? |
| Recall | TP / (TP + FN) | How many relevant items are selected? |
Intersection Over Union
Intersection over Union (IoU) is another important metric for image segmentation. It measures the overlap between the predicted segment and the ground truth segment.
The IoU is calculated as follows:
IoU = Area of Overlap / Area of Union
Here’s a quick breakdown:
- Area of Overlap: The area where the predicted and ground truth segments overlap.
- Area of Union: The total area covered by both the predicted and ground truth segments.
IoU values range from 0 to 1. A higher IoU indicates better segmentation performance.
Consider this simple example:
- Predicted Segment: 40 pixels
- Ground Truth Segment: 50 pixels
- Overlap: 30 pixels
- Union: 60 pixels
So, IoU = 30 / 60 = 0.5.
These metrics are essential for evaluating deep learning models in image segmentation. Use them to improve your model’s accuracy and reliability.
Future Of Image Segmentation
The future of image segmentation is bright. With deep learning, it is evolving fast. This advancement opens many new possibilities. We will see more precise and efficient solutions. These changes will impact various fields in significant ways.
Advancements In Technology
Technology is the key driver in image segmentation. Deep learning algorithms are getting smarter. They can now process images faster and more accurately. Neural networks play a big role in this. They are designed to learn from large datasets.
Convolutional Neural Networks (CNNs) are a game-changer. They can detect even the smallest details in images. Generative Adversarial Networks (GANs) are also gaining popularity. They help in creating high-quality images from low-quality ones.
Here is a table showing some key advancements:
| Technology | Impact |
|---|---|
| Convolutional Neural Networks (CNNs) | Better detail detection |
| Generative Adversarial Networks (GANs) | Improved image quality |
| Large Datasets | More accurate learning |
Potential Applications
The applications of image segmentation are vast. Healthcare is one of the biggest beneficiaries. Doctors can now get precise images of organs and tissues. This helps in better diagnosis and treatment.
Self-driving cars use image segmentation. They need to understand their environment. This technology helps them identify objects like pedestrians and other vehicles. It ensures safer driving.
Agriculture also benefits from this technology. Farmers use it to monitor crops. They can detect diseases early. This leads to better crop management.
Here is a list of potential applications:
- Healthcare
- Self-driving cars
- Agriculture
- Retail
- Robotics
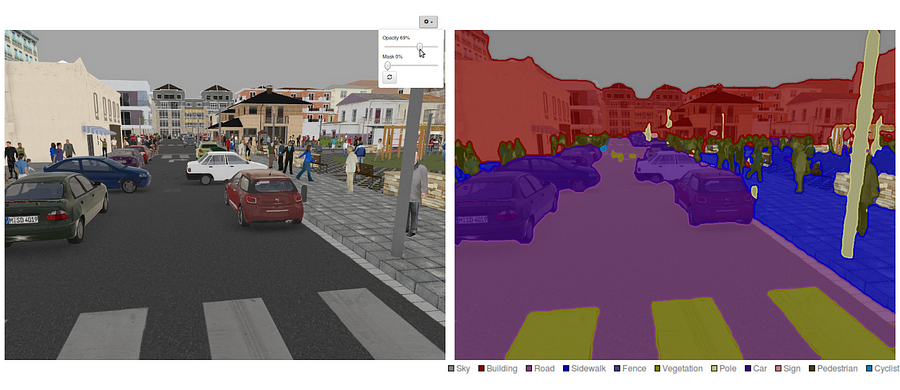
Credit: nanonets.com
Frequently Asked Questions
What Is Image Segmentation In Deep Learning?
Image segmentation in deep learning involves partitioning an image into distinct regions. Each region represents different objects or features. This process helps in identifying and analyzing specific parts of an image. It is crucial for tasks like object detection and image recognition.
Which Deep Learning Model Is Best For Segmentation?
The best deep learning model for segmentation is U-Net. It excels in medical imaging and provides precise results.
Can Cnn Be Used For Image Segmentation?
Yes, CNN can be used for image segmentation. It excels in identifying and classifying image regions efficiently.
What Is The Best Method For Image Segmentation?
The best method for image segmentation is the use of deep learning models like U-Net or Mask R-CNN. These models provide high accuracy and efficiency for complex images.
Conclusion
Deep learning has revolutionized image segmentation. It offers precise and efficient solutions for various applications. By leveraging advanced algorithms, businesses can achieve remarkable results. Understanding these techniques empowers developers to create powerful tools. Embrace deep learning for improved image analysis and stay ahead in the tech landscape.