

Save time and improve data quality with these automated cleaning techniques for EDA. Learn how to handle missing values, outliers, and inconsistencies efficiently. Optimize your data preparation process today!
By automating the data cleaning process, analysts can save time and ensure more accurate insights from their exploratory data analysis. In this blog post, we will explore the importance of automated data cleaning techniques in EDA and discuss some common methods used to clean and preprocess data efficiently.
Let’s delve into how these techniques can improve the overall quality and reliability of data analysis in various industries.
Introduction To Data Cleaning
Data cleaning is the first step in data analysis. It ensures data quality and reliability. Clean data leads to better insights.
Importance Of Data Cleaning
Data cleaning removes errors and inconsistencies. It prepares data for analysis. Here are some reasons why data cleaning is important:
- Improves accuracy of the results.
- Enhances data quality and reliability.
- Reduces bias in data analysis.
- Facilitates better decision-making processes.
Challenges In Manual Data Cleaning
Manual data cleaning is time-consuming. It requires attention to detail. Some common challenges include:
- Handling missing values.
- Identifying and correcting errors.
- Dealing with duplicate data.
- Ensuring data consistency.
Automated data cleaning techniques can address these challenges. They save time and improve efficiency.
Understanding Eda
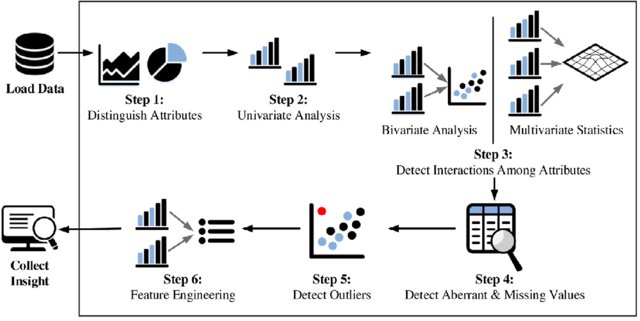
Exploratory Data Analysis (EDA) is a critical step in data science. It helps in understanding and summarizing the main characteristics of a dataset. EDA uses various techniques to maximize insights, detect anomalies, and check assumptions.
Role Of Eda In Data Analysis
EDA plays a crucial role in the data analysis process. It helps in identifying patterns, spotting anomalies, and testing hypotheses. EDA provides a better understanding of the dataset’s structure. This step is essential before applying any statistical modeling or machine learning algorithms.
Common Techniques In Eda
Several techniques are common in EDA. These techniques help in visualizing and summarizing the data effectively.
- Descriptive Statistics: Descriptive statistics summarize the main features of a dataset. They provide simple summaries about the sample and measures.
- Data Visualization: Data visualization involves creating visual representations of the data. Common tools include histograms, scatter plots, and box plots.
- Missing Value Analysis: This technique helps in identifying and handling missing values in the dataset. Various methods include deletion, imputation, or using algorithms that support missing values.
- Outlier Detection: Outlier detection identifies data points that significantly differ from other observations. Methods include the Z-score, IQR, and visualization techniques.
- Correlation Analysis: Correlation analysis determines the relationship between variables. It helps in understanding how variables are related to each other.
Here’s a simple table summarizing some EDA techniques:
| Technique | Description |
|---|---|
| Descriptive Statistics | Summarizes main features of a dataset |
| Data Visualization | Creates visual representations of data |
| Missing Value Analysis | Identifies and handles missing values |
| Outlier Detection | Identifies data points that differ significantly |
| Correlation Analysis | Determines the relationship between variables |
Automated Data Cleaning
Data cleaning is crucial for Exploratory Data Analysis (EDA). It ensures the accuracy and quality of data. Automated Data Cleaning simplifies this process. It uses algorithms and tools to handle data issues. This saves time and reduces human error.
What Is Automated Data Cleaning?
Automated Data Cleaning uses software to fix data problems. It detects and corrects errors without manual intervention. Common tasks include removing duplicates, filling missing values, and correcting data types.
This process relies on predefined rules and algorithms. It ensures consistency and accuracy in large datasets. Automated tools can handle data from various sources and formats.
Benefits Of Automation
Automation offers several advantages:
- Efficiency: It processes data faster than manual methods.
- Consistency: Ensures uniform data cleaning across all datasets.
- Accuracy: Reduces human errors in data handling.
- Scalability: Handles large volumes of data effortlessly.
Automated cleaning tools can integrate with other data processing systems. This makes the entire data pipeline more efficient. It allows data scientists to focus on analysis rather than cleaning.
| Feature | Manual Cleaning | Automated Cleaning |
|---|---|---|
| Speed | Slow | Fast |
| Consistency | Varies | High |
| Error Rate | High | Low |
| Scalability | Limited | High |
Techniques In Automated Data Cleaning
Automated data cleaning is crucial for effective Exploratory Data Analysis (EDA). It ensures the data is accurate and reliable. This blog section discusses key techniques in automated data cleaning.
Outlier Detection
Outliers can distort your data analysis. Detecting and handling them is essential. Automated techniques for outlier detection include:
- Z-Score Method: Calculates the z-score for each data point. Points with z-scores beyond a threshold are outliers.
- IQR Method: Uses the Interquartile Range (IQR) to identify outliers. Points outside 1.5 times the IQR are flagged.
- Isolation Forest: An algorithm that isolates anomalies. It is effective for high-dimensional data.
These methods help in identifying anomalies. This ensures cleaner and more accurate data for analysis.
Missing Value Imputation
Missing values can skew your data analysis. Proper imputation of missing values is vital. Common automated techniques include:
- Mean/Median Imputation: Replaces missing values with the mean or median of the column.
- K-Nearest Neighbors (KNN): Estimates missing values based on the nearest neighbors.
- Multiple Imputation: Generates multiple imputed datasets and combines them. It accounts for uncertainty in the imputations.
Using these techniques ensures that missing values don’t compromise your analysis. It helps in maintaining the integrity of the dataset.
Tools For Automated Data Cleaning
Data cleaning is a crucial step in Exploratory Data Analysis (EDA). Automated tools simplify this process, saving time and reducing errors. This section explores popular software for automated data cleaning. We will also compare these tools to help you choose the best one for your needs.
Popular Software
Several tools are available for automated data cleaning. Some of the most popular are:
- OpenRefine: A powerful tool for working with messy data. It helps you clean, transform, and extend data with web services.
- Trifacta Wrangler: An intuitive tool for data wrangling. It provides visual guidance for cleaning data.
- DataCleaner: An open-source data quality solution. It helps you profile, clean, and transform data.
- Talend Data Quality: A comprehensive suite for data profiling and cleaning. It integrates well with other Talend products.
- Alteryx: A robust platform for data blending and advanced analytics. It offers extensive data preparation capabilities.
Comparison Of Tools
Below is a comparison of these popular tools based on key features:
| Tool | Ease of Use | Key Features | Integration |
|---|---|---|---|
| OpenRefine | Medium | Data cleaning, transformation, web services | Limited |
| Trifacta Wrangler | High | Visual guidance, data wrangling | Good |
| DataCleaner | Medium | Data profiling, cleaning, transformation | Good |
| Talend Data Quality | Medium | Profiling, cleaning, integration | Excellent |
| Alteryx | High | Data blending, analytics | Excellent |
Choosing the right tool depends on your specific needs. Consider ease of use, key features, and integration capabilities.
Credit: www.analyticsvidhya.com
Integration With Eda
Integrating automated data cleaning techniques with Exploratory Data Analysis (EDA) ensures accurate and reliable data insights. This integration streamlines the EDA process, making it more efficient and effective.
Seamless Workflow
Automated data cleaning integrates smoothly with EDA, providing a seamless workflow. The process involves:
- Removing duplicates
- Filling missing values
- Correcting data types
These steps ensure that the data is ready for analysis. A clean dataset reduces errors and enhances the quality of insights.
Enhanced Efficiency
Automated data cleaning enhances efficiency in EDA. It saves time and reduces manual effort. With automation, analysts can focus on:
- Interpreting data
- Identifying patterns
- Generating insights
Automated tools can handle large datasets quickly. This speeds up the EDA process significantly.
| Manual Cleaning | Automated Cleaning |
|---|---|
| Time-consuming | Time-efficient |
| Prone to errors | Reduces errors |
| Labor-intensive | Less manual effort |
Efficient data cleaning leads to better EDA outcomes. It ensures that the insights drawn are accurate and reliable.
Case Studies
Discover how automated data cleaning techniques streamline Exploratory Data Analysis (EDA) in our latest case studies. Learn efficient methods to enhance data quality and accelerate analysis.
Industry Examples
Success Stories
Case studies offer valuable insights into automated data cleaning techniques in EDA. Let’s delve into real-world scenarios to understand the impact.
Industry Examples
Healthcare Sector: A hospital streamlined patient records using automated data cleaning, enhancing efficiency.
E-commerce: An online retailer boosted sales by removing duplicate entries through automated data cleaning.
Success Stories
Financial Services: A bank minimized errors in financial reports via automated data cleaning, improving compliance.
Education Sector: A university optimized student data accuracy, leading to better decision-making processes.

Credit: docs.aws.amazon.com
Future Of Data Cleaning
Automated data cleaning techniques have revolutionized data analysis by streamlining processes and ensuring data accuracy.
Emerging Trends
Innovative AI algorithms are reshaping data cleaning methods.
Predictions
Data cleaning will become fully automated, enhancing efficiency.

Credit: www.researchgate.net
Frequently Asked Questions
What Is Data Cleaning In Eda?
Data cleaning in EDA involves removing or correcting inaccuracies, inconsistencies, and missing values in datasets. This ensures reliable analysis.
What Are The Techniques Used In Eda?
Techniques used in EDA include data visualization, summary statistics, data cleaning, correlation analysis, and feature engineering. Visualization tools like histograms, scatter plots, and box plots help reveal patterns. Summary statistics provide insights into data distribution. Data cleaning addresses missing values and outliers.
Correlation analysis identifies relationships between variables. Feature engineering creates new relevant variables.
How To Automate The Data Cleaning Process?
Use Python libraries like Pandas and NumPy for data cleaning. Employ automation tools like Apache NiFi. Utilize scripts to handle repetitive tasks. Leverage machine learning for anomaly detection. Integrate workflows with cloud services.
What Are Some Data Cleaning Techniques?
Data cleaning techniques include removing duplicates, correcting errors, filling missing values, standardizing formats, and validating data accuracy.
Conclusion
Mastering automated data cleaning techniques enhances EDA efficiency. It saves time and improves data accuracy. Implementing these methods ensures cleaner datasets. This leads to more reliable analysis and insights. Stay updated with the latest tools and strategies. Efficient data cleaning sets the foundation for successful data-driven decisions.