

Design robust ETL pipelines using SQL for seamless data integration. Learn to extract, transform, and load data efficiently. Automate your data preparation process. Click to enhance your ETL skills now!
In data science, ELT (Extract, Load, Transform) pipelines are critical for managing vast datasets. SQL, a powerful query language, plays a pivotal role in constructing these pipelines. It facilitates the extraction of raw data from various sources, loads it into a centralized data warehouse, and transforms it into a usable format for analysis.
By leveraging SQL, data scientists can automate and optimize these processes, ensuring data integrity and accelerating insights. This approach not only saves time but also improves the accuracy of data-driven decisions, making it indispensable in modern data science workflows.
Introduction To Elt Pipelines
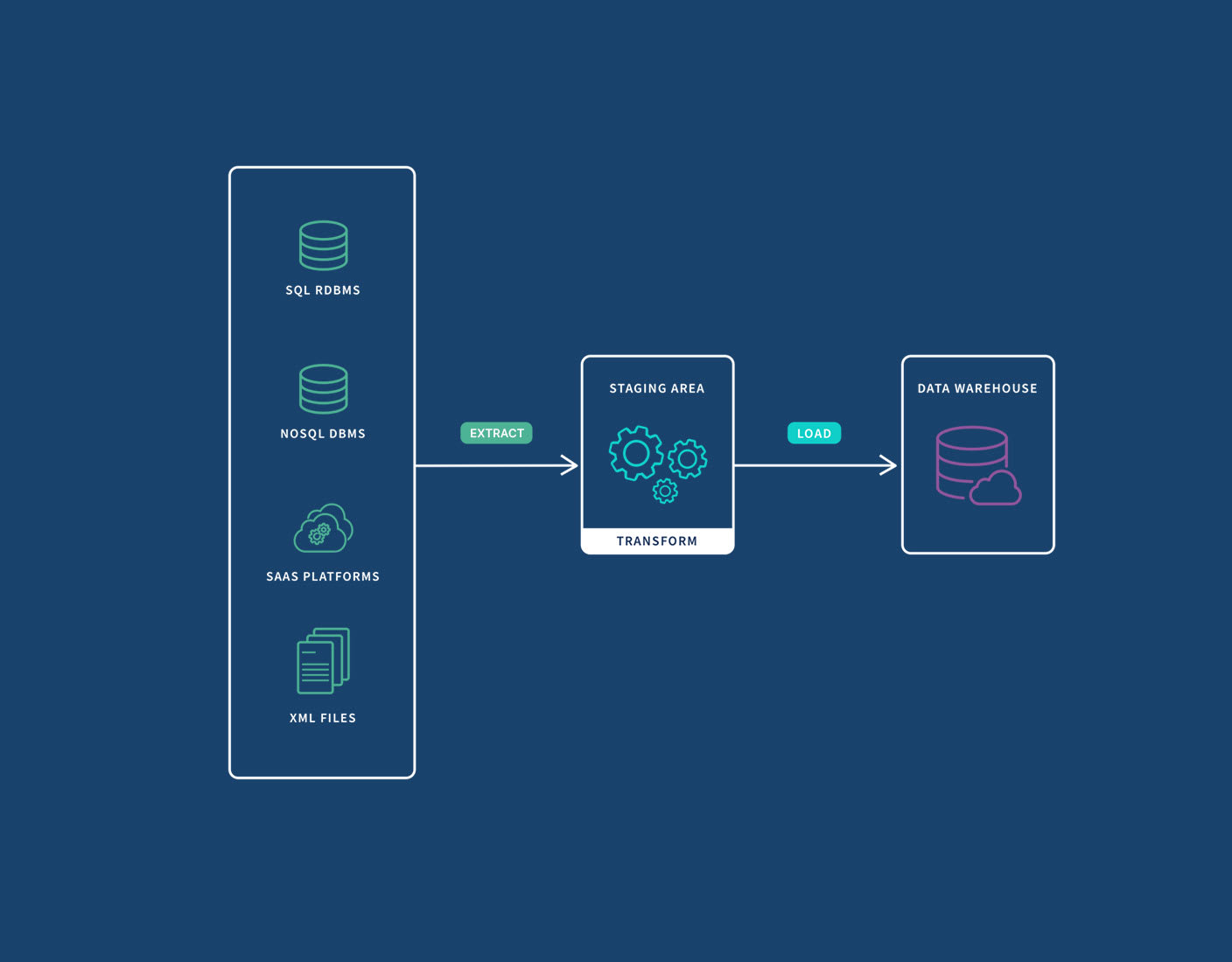
ELT stands for Extract, Load, Transform. It is a process in data science. First, data is extracted from source systems. Then, it is loaded into a data warehouse. Finally, data is transformed into useful formats.
ELT is fast and efficient. Large datasets are handled easily. It uses the power of the data warehouse. This makes transformations quicker. Scalability is another benefit. ELT can grow with your data needs. It also simplifies the data pipeline. Less movement of data means fewer errors.
Core Components Of Elt
Data is taken from different sources. These sources could be databases, APIs, or files. It is important to get data quickly. This step ensures the data is ready for the next phase.
Data is placed into a data warehouse. The warehouse stores large amounts of data. This phase happens after extraction. The data is now ready to be transformed.
Data is cleaned and organized. This makes the data useful for analysis. SQL is often used in this phase. The data becomes more meaningful and easy to understand.
Choosing The Right Tools
SQL tools help in managing data. These tools are easy to use. Some popular SQL tools include MySQL, PostgreSQL, and SQLite. MySQL is great for large databases. PostgreSQL is known for its advanced features. SQLite is good for small projects.
| Tool | Best For | Features |
|---|---|---|
| MySQL | Large Databases | High Performance, Scalability |
| PostgreSQL | Advanced Features | Extensible, Supports Advanced Queries |
| SQLite | Small Projects | Lightweight, Easy Setup |
Designing The Pipeline Architecture
Data pipelines start with data sources. These can be databases, APIs, or files. The pipeline moves data from these sources to destinations. Destinations could be data warehouses, data lakes, or analytics platforms. Properly choosing sources and destinations is key. Quality of data must be ensured. Always use reliable and consistent data sources.
Workflow orchestration is the process of managing tasks. Tools like Apache Airflow and Prefect help. They schedule and monitor pipeline tasks. Tasks include extracting, loading, and transforming data. Orchestrators ensure tasks run in the correct order. They also handle task dependencies. Workflow orchestration is crucial for efficient data pipelines.
Writing Efficient Sql Queries
Use SELECT statements to get only needed columns. Avoid using SELECT \, which is slow. Indexing can make queries faster. Use indexes on important columns. Filter data using WHERE clauses to reduce rows. Join tables carefully to avoid slow queries.
Break tasks into small steps. Use CTE (Common Table Expressions) for better readability. Avoid nested subqueries as they are slow. Use window functions for calculations across rows. Aggregate data with GROUP BY and HAVING clauses. Use functions like SUM(), AVG(), and COUNT() wisely.
Handling Data Quality
Data validation ensures data accuracy. Duplicate records can be removed. Missing values should be filled or discarded. Data type checks confirm correct formats. Range checks ensure values fall within expected limits. Uniqueness checks prevent duplicate entries. Consistency checks maintain uniformity across datasets.
Logging errors helps track issues. Alerts notify teams about problems. Retry mechanisms attempt to fix temporary issues. Fallback procedures ensure system stability. Error categorization helps in prioritizing fixes. Automated scripts can correct common errors. Regular audits ensure ongoing data quality.
Monitoring And Maintenance
Tracking pipeline performance is crucial. It ensures data flows smoothly and accurately. Use monitoring tools to keep an eye on data transfer rates. Set up alerts for any anomalies or failures. This helps in quickly identifying issues. Regular checks on performance metrics can prevent downtime. Keep logs for future reference and troubleshooting. Use dashboards to visualize pipeline health.
Performing routine maintenance is essential. It ensures the pipeline runs efficiently. Clean up temporary files to save space. Update scripts and tools to the latest versions. Check for data quality issues regularly. Validate data integrity and fix any inconsistencies. Backup important data periodically. Ensure security protocols are up to date. Regularly review pipeline configurations and optimize as needed.

Credit: www.qlik.com
Real-world Use Cases
Building ELT pipelines with SQL for data science streamlines data processing, enabling efficient analysis and actionable insights. Companies leverage SQL pipelines to integrate, transform, and load data seamlessly, enhancing decision-making.
Case Study: E-commerce Data
E-commerce stores gather lots of data. SQL helps process this data. Customer purchase patterns can be analyzed. This helps in targeted marketing. Sales data can show which items are popular. Inventory can be managed better. Customer feedback can be stored and analyzed. This improves customer satisfaction.
Case Study: Financial Analytics
Banks and financial firms use SQL for data analysis. Transaction data can be processed quickly. Fraud detection becomes easier. SQL helps in risk management. Financial reports can be generated easily. Investment trends can be analyzed. This helps in making better financial decisions.
Future Trends In Elt
Automation is revolutionizing ELT pipelines. AI integration helps in optimizing data processing. This reduces human errors. Machine learning models improve data quality. AI tools can detect anomalies. They provide real-time insights. Automated systems save time. They enhance efficiency. Predictive analytics becomes more accurate. AI-driven ELT pipelines are the future.
Scalability is crucial for handling big data. Cloud solutions offer flexible storage. They provide scalable computing power. Data lakes and data warehouses are easily managed in the cloud. Cloud platforms support diverse data sources. They ensure seamless data integration. Cloud-based ELT pipelines are cost-effective. They offer robust security. Businesses can scale up or down as needed. This reduces infrastructure costs.

Credit: www.amazon.com
Credit: www.qlik.com
Frequently Asked Questions
How To Build An Etl Pipeline In Sql?
To build an ETL pipeline in SQL, extract data from sources, transform it using SQL queries, and load it into a database. Use tools like Apache Airflow for scheduling and monitoring. Ensure data quality checks are in place. Optimize performance by indexing and partitioning.
Can Etl Be Done With Sql?
Yes, ETL can be done with SQL. SQL can extract, transform, and load data efficiently. Many databases support SQL-based ETL processes.
Can I Use Sql For Data Science?
Yes, you can use SQL for data science. SQL efficiently handles data extraction, manipulation, and querying from databases. It is essential for managing large datasets and integrating with other data analysis tools.
What Is The Best Language For Etl Pipeline?
Python is the best language for ETL pipelines. It offers extensive libraries, ease of use, and strong community support.
Conclusion
Mastering SQL for ELT pipelines can transform your data science projects. It ensures efficient data handling and analysis. Implementing these techniques boosts productivity and delivers faster insights. Stay ahead in data science by leveraging SQL for your ELT needs. Start building robust ELT pipelines with SQL today and see the difference.