

Hierarchical Clustering in Python is a method for clustering data points into nested clusters. It can be performed using libraries like SciPy and scikit-learn.
Hierarchical Clustering creates a tree-like structure of clusters, called a dendrogram. This method is particularly useful for understanding the relationships among data points. Two main types exist: Agglomerative (bottom-up) and Divisive (top-down). Agglomerative clustering starts with individual data points and merges them into larger clusters.
Divisive clustering begins with a single cluster and splits it into smaller clusters. Python libraries such as SciPy and scikit-learn provide efficient tools for implementing this clustering technique. Hierarchical Clustering is ideal for tasks requiring a clear visualization of data relationships.
Introduction To Hierarchical Clustering
Hierarchical clustering is a method of cluster analysis. It builds a hierarchy of clusters. This technique is useful for data analysis. It helps in finding patterns and similarities in data. This method can be divided into two types: agglomerative and divisive. Agglomerative clustering is a bottom-up approach. Divisive clustering is a top-down approach. Both methods help in organizing data into meaningful groups.
Clustering groups data points into clusters. These clusters have similar characteristics. It is important in machine learning and data mining. Clustering helps in understanding the structure of data. It also reveals hidden patterns. This technique is widely used in various fields. Examples include marketing, biology, and social science. Clustering makes data more interpretable and useful.
| Feature | Hierarchical Clustering | Other Clustering Techniques |
|---|---|---|
| Approach | Builds a hierarchy | Does not build a hierarchy |
| Types | Agglomerative, Divisive | K-means, DBSCAN |
| Flexibility | More flexible | Less flexible |
| Complexity | Higher complexity | Lower complexity |
| Data Size | Small to medium | Large datasets |
Credit: www.w3schools.com
Fundamentals Of Hierarchical Clustering
Similarity measures how alike two data points are. Data points that are close together are more similar. Distance metrics help in finding similarity. Common metrics include Euclidean distance and Manhattan distance.
Hierarchical clustering has two main types. Agglomerative clustering starts with each point as a single cluster. Then, it merges clusters step by step. Divisive clustering starts with one big cluster. Then, it splits clusters step by step. Both methods create a tree-like structure called a dendrogram.
Setting The Stage With Python
Dive into hierarchical clustering using Python to uncover hidden patterns in data. Learn step-by-step techniques for effective data segmentation. Boost your data analysis skills with practical Python examples.
Python Ecosystem For Data Science
Python is a popular language for data science. It has many powerful libraries. These libraries help in data analysis and visualization. Pandas is used for data manipulation. NumPy helps with numerical operations. Matplotlib and Seaborn are great for plotting.
Required Libraries And Installations
To start hierarchical clustering, some libraries are needed. Install Scipy and Scikit-learn. These libraries provide functions for clustering. Use the pip command to install them:
pip install scipy scikit-learn
You also need Matplotlib to visualize the clusters. Use the following command:
pip install matplotlib
Once installed, you can import these libraries. This makes it easy to start coding right away.
Data Preparation For Clustering
Choosing the right data is crucial for clustering. Select relevant features that impact the outcome. Remove missing values and handle outliers to clean the data. This ensures accurate clustering results. Standardize the data to maintain consistency.
Feature selection helps in reducing the dimensionality of the data. This makes the clustering process faster. Transform features to a uniform scale. Normalization or scaling are common techniques. Transformations help in improving the performance of clustering algorithms.
Executing Hierarchical Clustering In Python
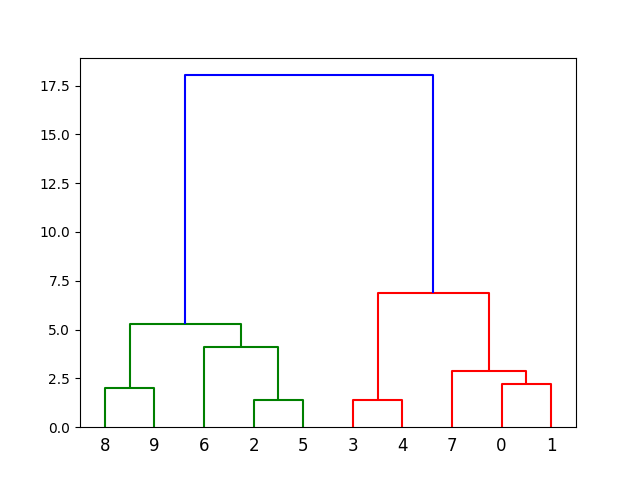
A dendrogram shows the clustering process. It helps to visualize how clusters are formed. Use the `scipy` library in Python. Import `dendrogram` and `linkage` from `scipy.cluster.hierarchy`. Prepare your data. Choose a linkage method. Fit the linkage method to your data. Plot the dendrogram using `plt.figure()` and `dendrogram()`. Label the axes for clarity. This helps to see the hierarchical structure of data.
Linkage methods decide how clusters are formed. Common methods include:
- Single Linkage: Uses the shortest distance.
- Complete Linkage: Uses the longest distance.
- Average Linkage: Uses the average distance.
- Ward’s Method: Minimizes variance within clusters.
Choose the method that fits your data best. Each method has its own advantages. Experiment with different methods. This helps find the most suitable one for your data.
Interpreting The Results
Interpreting the results of hierarchical clustering in Python involves analyzing dendrograms to identify meaningful clusters. This process helps reveal data structure and relationships, enhancing insights for decision-making.
Analyzing Cluster Distributions
Clusters are groups of similar items. Clusters help us understand patterns in data. Each cluster should be unique. Check if clusters overlap. Overlapping clusters are not good. Small clusters might be noise. Big clusters show common patterns. Plot clusters to see them better. Use colors to separate clusters. Colors make it easy to see. Each cluster has a center. The center represents the average. Look at the distance to the center. Short distances mean items are similar.
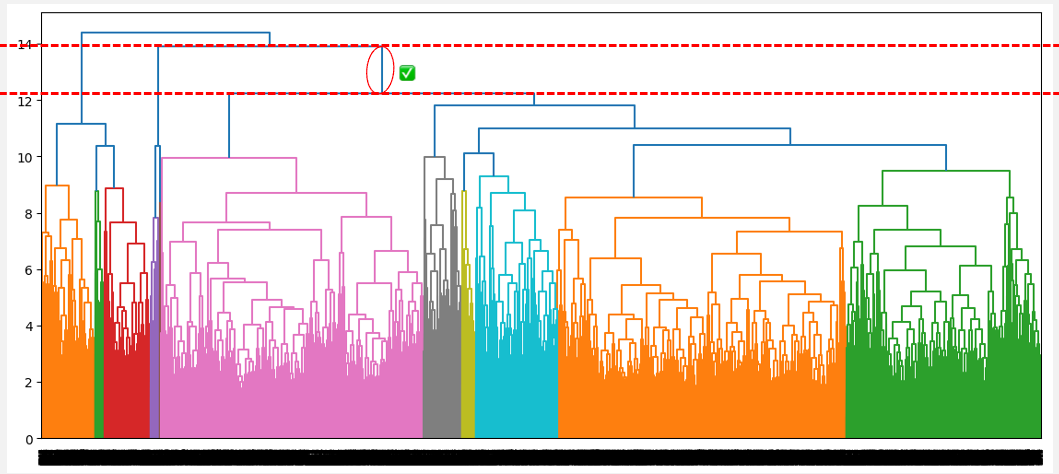
Identifying Optimal Cluster Numbers
Finding the right number of clusters is important. Too many clusters can be confusing. Too few clusters might miss details. Use the Elbow Method. Plot the number of clusters against total distance. Look for a bend in the plot. The bend shows the best number of clusters. Another way is the Silhouette Score. Higher scores are better. Scores close to 1 are best. Scores close to 0 are bad. Try different numbers of clusters. Compare their scores. Choose the number with the best score.
Case Studies And Applications
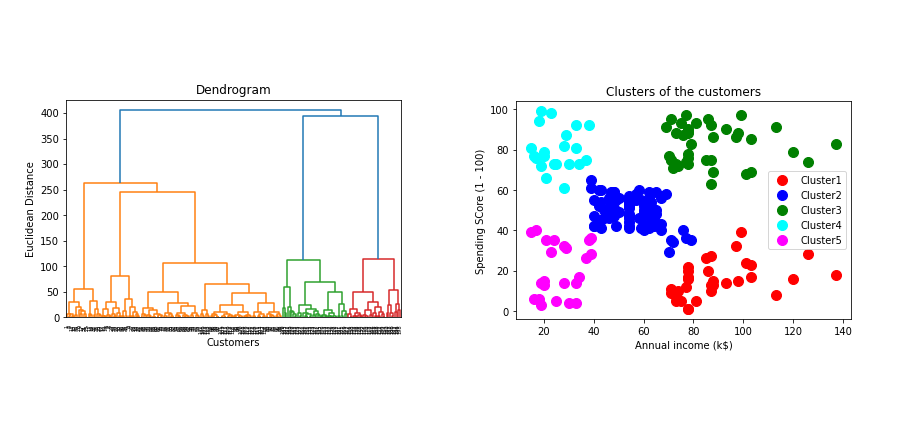
Retail stores use hierarchical clustering to group customers. This helps in understanding customer behavior. Customer segments can be created based on buying patterns. Stores can then target specific groups with special offers. For example, customers who buy baby products often may get promotions for baby food. This helps in personalized marketing and improves customer satisfaction.
Hierarchical clustering is also used in genomics. It helps in grouping similar genes or DNA sequences. Scientists can identify patterns in genomic data. This aids in disease research and drug development. Clustering can show how certain genes are related. This makes it easier to study genetic disorders. Grouping similar data helps in finding new insights.
Credit: www.datacamp.com
Optimizing Hierarchical Clustering
Reducing data dimensions can boost performance. Principal Component Analysis (PCA) is helpful. Agglomerative clustering works well with small datasets. For large datasets, divisive clustering is better. Linkage criteria choice matters a lot. Ward’s method minimizes variance. Single linkage uses minimum distance. Complete linkage uses maximum distance. Average linkage averages all distances.
Hierarchical clustering struggles with large datasets. Sampling methods can help. Random sampling picks random points. Stratified sampling ensures good distribution. Incremental clustering is another method. This method divides data into chunks. Parallel computing speeds up the process. Dask and Spark are useful tools. Memory management is crucial. Use efficient data structures.
Visualizing Clusters For Insights
2D plots help in visualizing clusters on a flat plane. This makes it easy to see groupings. 3D plots add more depth. They show clusters in three dimensions. This gives a better perspective of data. Matplotlib and Seaborn are great for these plots. They are easy to use and very popular. 2D plots are simpler. 3D plots need more understanding. They give more insights.
Heatmaps show data intensity. They use different colors to show values. Cluster maps combine heatmaps and dendrograms. This shows both value intensity and cluster structure. Seaborn is very useful for these. It makes creating heatmaps easy. Cluster maps need more data but give more insights.
Credit: towardsai.net
Challenges And Considerations
Noise and outliers can confuse the clustering process. It is important to handle them properly. Noise refers to random errors or variations in the data. Outliers are data points that differ significantly from other observations. Techniques like data cleaning and preprocessing can help. Removing or correcting noise and outliers ensures better clustering results.
Robustness means the clustering results are stable and reliable. Reproducibility ensures that the same results can be obtained again. It is crucial to set a random seed in your code. Document all steps clearly for others to follow. Using standardized methods and tools helps maintain reproducibility. This way, your clustering results will be trusted.
Beyond Basics: Advanced Techniques
Integrating hierarchical clustering into machine learning pipelines can improve model accuracy. This method helps in identifying data patterns. Use it to preprocess data before training a model. Combine it with dimensionality reduction techniques like PCA. This will simplify your data and make it more manageable. You can also use it for feature engineering. Create new features based on cluster assignments. This enriches the dataset and can improve performance.
Combining hierarchical clustering with other methods yields better results. Use K-means after hierarchical clustering to refine clusters. This approach is called hybrid clustering. It improves both speed and accuracy. Another technique is ensemble clustering. Here, you combine results from multiple clustering algorithms. This adds robustness to your model. Each method brings its strengths, creating a more reliable outcome.
Conclusion And Future Directions
Hierarchical clustering in Python offers robust data grouping capabilities. Future advancements could improve algorithm efficiency and integration with other machine learning techniques.
Summarizing Key Takeaways
Hierarchical clustering groups data based on similarity. It is easy to understand. It does not require the number of clusters beforehand. This method is good for small datasets. It can show the relationships between data points. Dendrograms help visualize these relationships. Hierarchical clustering can be sensitive to noise. It may not work well with large datasets. Pre-processing data can improve results. Proper distance metrics are important for accuracy.
Emerging Trends In Clustering
New trends in clustering are exciting. Deep learning is combined with clustering. This improves accuracy. Big data technologies help with large datasets. Faster algorithms are being developed. These are more efficient and scalable. Real-time clustering is becoming popular. It helps in dynamic environments. New techniques are being researched. They focus on better handling of noise. Hybrid models are also emerging. These combine different clustering methods. They aim to get the best results.
Frequently Asked Questions
What Is Hierarchical Clustering In Python?
Hierarchical clustering in Python groups similar data points into nested clusters. It uses methods like agglomerative or divisive clustering. Libraries such as SciPy and scikit-learn provide tools for implementation. This technique helps visualize data relationships in a dendrogram. It’s useful for exploratory data analysis.
What Is Hierarchical K Clustering In Python?
Hierarchical K clustering in Python groups data into clusters using a nested approach. It builds a tree-like structure. The `scipy. cluster. hierarchy` module provides tools for this. Use `linkage` for clustering and `dendrogram` for visualization. This method helps identify natural groupings in data.
What Are The Two 2 Types Of Hierarchical Clustering?
The two types of hierarchical clustering are agglomerative and divisive. Agglomerative clustering merges clusters, while divisive clustering splits them.
What Is An Example Of Hierarchical Clustering?
An example of hierarchical clustering is grouping animals based on traits like size, habitat, and diet. This method organizes data into a tree-like structure, showing relationships and clusters at various levels. It helps in identifying natural groupings within a dataset.
Conclusion
Hierarchical clustering in Python offers a powerful way to analyze data. Its simplicity and effectiveness make it accessible. By following this guide, you can leverage its capabilities to uncover patterns. Start experimenting with your datasets to see the results. Happy clustering!