Tackle EDA challenges in big data environments with our comprehensive guide. Learn distributed computing techniques, sampling strategies, and efficient algorithms for large-scale data exploration.
Big data analytics is crucial for businesses seeking valuable insights from massive datasets. Scalable EDA methods play a vital role in enhancing data processing speed and accuracy. By utilizing these methods, organizations can extract meaningful information from diverse sources and make data-driven decisions.
This blog will delve into the significance of scalable EDA methods in the realm of big data analytics, exploring their benefits and applications across various industries.
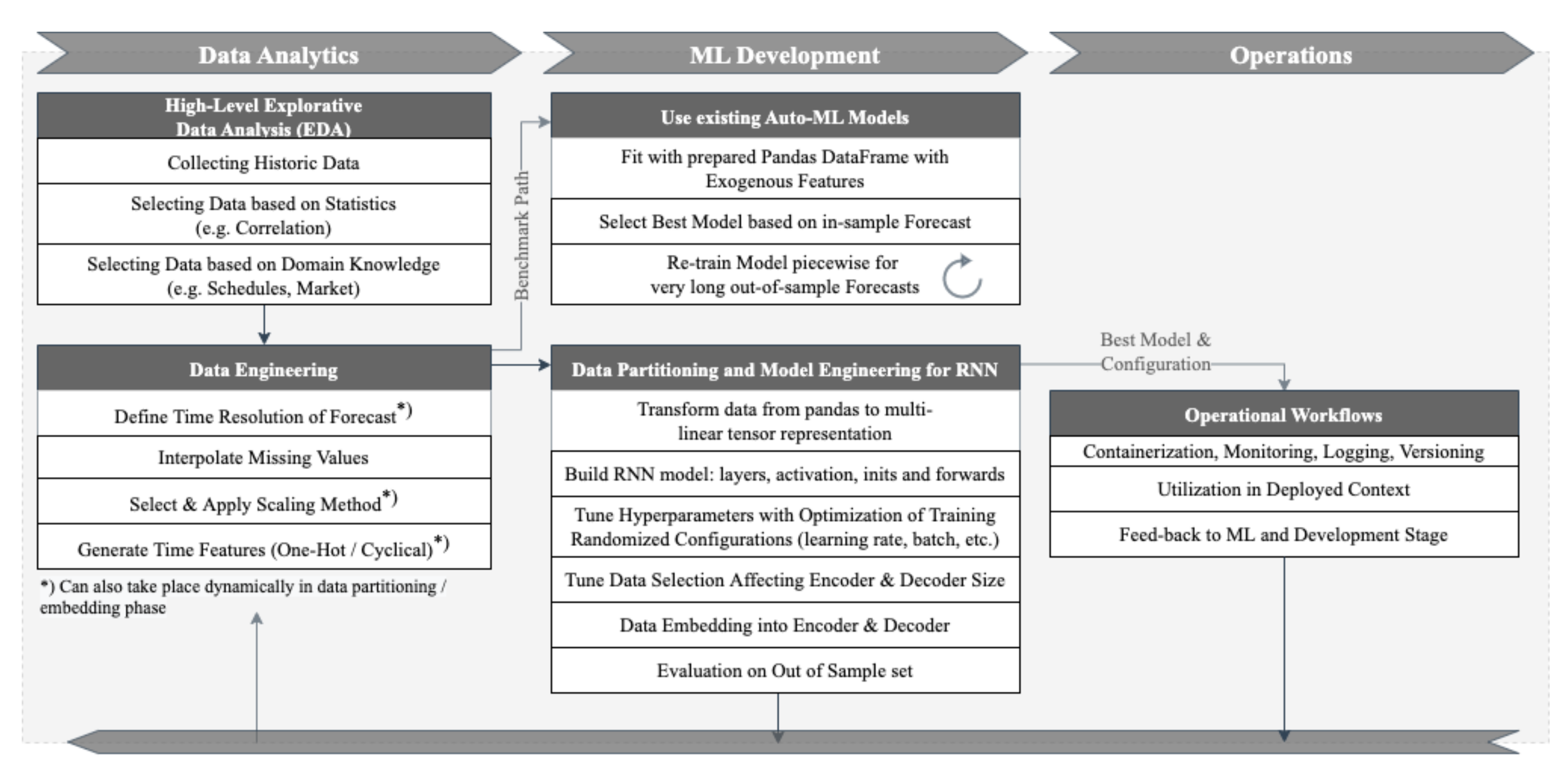
Credit: www.mdpi.com
Introduction To Scalable Eda
Exploratory Data Analysis (EDA) is a crucial step in the data science process. With the rise of Big Data, traditional EDA methods struggle to handle vast datasets. Scalable EDA methods are essential for efficient analysis in such scenarios.
Importance In Big Data
Big Data consists of large and complex datasets. These datasets require specialized tools for analysis. Scalable EDA helps in processing and visualizing these huge datasets. This leads to better insights and data-driven decisions.
Traditional EDA tools fall short due to resource limitations. Scalable methods overcome these hurdles. They enable the handling of petabytes of data seamlessly. This ensures comprehensive data exploration.
Key Challenges
Implementing Scalable EDA comes with its own set of challenges:
- Data Volume: Handling large volumes of data requires robust infrastructure.
- Data Variety: Big Data includes structured, unstructured, and semi-structured data.
- Real-time Processing: Many applications need real-time data analysis.
- Resource Management: Efficient resource allocation is crucial for scalability.
| Challenge | Description |
|---|---|
| Data Volume | Requires robust infrastructure to handle large datasets. |
| Data Variety | Includes structured, unstructured, and semi-structured data. |
| Real-time Processing | Necessary for applications needing real-time analysis. |
| Resource Management | Efficient resource allocation is crucial for scalability. |
Addressing these challenges is vital. It ensures the effective implementation of Scalable EDA methods. This leads to accurate and timely insights from Big Data.
Fundamental Concepts
Understanding the fundamental concepts behind scalable exploratory data analysis (EDA) methods is crucial. These concepts help in processing big data efficiently. Let’s explore some key areas.
Exploratory Data Analysis
Exploratory Data Analysis (EDA) involves summarizing the main features of data. EDA uses visual methods. It aims to uncover patterns, spot anomalies, and test hypotheses.
Tools like histograms, bar charts, and scatter plots help in EDA. These tools make data comprehensible. EDA also includes using statistical techniques. Techniques like mean, median, and mode are common.
A simple EDA workflow might include:
- Data Collection
- Data Cleaning
- Data Visualization
- Summarizing Statistics
Scalability In Analytics
Scalability is the ability to handle growing data volumes efficiently. In big data analytics, scalability is key. It ensures that the analysis remains effective as data grows.
There are two main types of scalability:
| Type | Description |
|---|---|
| Vertical Scalability | Adding resources to a single node. |
| Horizontal Scalability | Adding more nodes to the system. |
Tools and frameworks like Apache Hadoop and Spark support scalability. They distribute data across clusters. This distribution makes processing faster and more efficient.
Scalable EDA methods must consider resource allocation. Efficient resource use ensures optimal performance. Load balancing and data partitioning are vital techniques.
Techniques And Tools
Big data analytics requires efficient techniques and tools to handle vast datasets. Scalability is crucial. Below are effective methods and tools used for scalable EDA.
Data Sampling Methods
Data sampling helps manage large datasets. It involves selecting a subset of data. This makes computations faster and easier.
Here are some common data sampling methods:
- Random Sampling: Randomly selects a portion of the data.
- Stratified Sampling: Ensures each subgroup is represented.
- Systematic Sampling: Selects data at regular intervals.
Data sampling reduces the time and resources needed for analysis. It maintains representativeness of the full dataset.
Distributed Computing
Distributed computing splits tasks across multiple machines. This speeds up data processing. It is essential for big data analytics.
Some popular distributed computing tools include:
| Tool | Description |
|---|---|
| Apache Hadoop | Processes large data sets using a cluster of computers. |
| Apache Spark | Faster than Hadoop, uses in-memory processing. |
| Google BigQuery | Cloud-based tool for big data analytics. |
Distributed computing makes handling big data more efficient. It enhances performance and scalability.
Optimizing Data Storage
Big data analytics demands efficient data storage. Optimizing data storage ensures quick access and processing. This boosts performance and saves resources. Let’s explore key methods for optimizing data storage.
Efficient Data Structures
Efficient data structures play a crucial role in data storage. They organize data logically and minimize space usage. Some popular data structures include:
- Hash Tables: Quick data retrieval using key-value pairs.
- B-Trees: Efficiently manage sorted data for fast queries.
- Graphs: Represent relationships between data points.
Choosing the right data structure is critical. It improves data access speed and reduces storage costs.
Compression Techniques
Compression techniques reduce the storage size of data. They make data more manageable and save space. Common compression methods include:
- Lossless Compression: No data is lost. Examples are ZIP and GZIP.
- Lossy Compression: Some data is lost. Examples are JPEG and MP3.
Compression techniques can be combined. This further optimizes storage and enhances data processing speed.
| Technique | Description | Example |
|---|---|---|
| Lossless Compression | No data loss | ZIP, GZIP |
| Lossy Compression | Some data loss | JPEG, MP3 |
Implementing these methods in your big data strategy is essential. It ensures efficiency and scalability in your analytics workflow.
Visualization Methods
Visualization methods are vital for understanding big data. They make complex datasets clear and actionable. With scalable EDA methods, you can handle large volumes of data effectively.
High-dimensional Data
High-dimensional data is challenging to visualize. It contains many variables, sometimes hundreds or thousands. Standard charts and graphs often fall short. Specialized techniques are necessary to present this data effectively.
One common method is the parallel coordinates plot. It helps visualize multidimensional data efficiently. Each axis represents a different variable. Lines connect the data points across these axes.
Another useful technique is the t-SNE (t-distributed Stochastic Neighbor Embedding). It reduces dimensions while preserving relationships between data points. This method helps in clustering and pattern recognition.
Here’s a quick comparison of techniques:
| Method | Use Case |
|---|---|
| Parallel Coordinates Plot | Visualizing multiple variables |
| t-SNE | Dimensionality reduction, clustering |
Real-time Dashboards
Real-time dashboards are crucial for monitoring big data. They provide instant insights and allow quick decisions. These dashboards update continuously, reflecting the latest data.
Key components of a real-time dashboard include:
- Data Streams: Continuous data flow from various sources.
- Widgets: Visual elements like charts, graphs, and gauges.
- Alerts: Notifications for significant changes or anomalies.
Building an effective real-time dashboard involves selecting the right tools. Some popular options are:
- Grafana
- Tableau
- Power BI
These tools offer diverse visualization options. They are user-friendly and integrate well with different data sources.
Real-time dashboards keep your team informed. They help in making swift, data-driven decisions.
Case Studies
Exploring scalable EDA methods for big data analytics can be insightful. This section dives into real-world applications and success stories. It sheds light on how various industries leverage these methods. The cases highlight the effectiveness and transformative potential of scalable EDA.
Industry Applications
Different industries benefit from scalable EDA methods. Here are some examples:
| Industry | Application |
|---|---|
| Healthcare | Analyzing patient data to predict disease outbreaks. |
| Finance | Detecting fraudulent transactions in real-time. |
| Retail | Optimizing inventory based on sales trends. |
| Telecommunications | Improving network performance using customer data. |
Success Stories
Several companies have seen significant improvements using scalable EDA methods.
- Healthcare Inc.: Reduced patient wait times by 30%.
- Finance Corp.: Decreased fraud by 50% in one year.
- Retail Solutions: Increased sales by 20% during peak seasons.
- Telecom Ltd.: Enhanced network uptime by 15%.
These success stories demonstrate the practical benefits. Scalable EDA methods enable better decision-making and efficiency. The industries highlighted show diverse applications and positive outcomes.
Best Practices
When implementing scalable EDA methods for big data analytics, following best practices is crucial. These practices include Algorithm Selection and Performance Tuning.
Algorithm Selection
- Choose algorithms based on data structure and problem complexity.
- Consider scalability, interpretability, and computational efficiency.
- Opt for algorithms that can handle large datasets and parallel processing.
Performance Tuning
- Optimize algorithm parameters for speed and accuracy.
- Utilize distributed computing frameworks for enhanced performance.
- Monitor and adjust resource allocation for efficient processing.
Credit: www.analyticsvidhya.com

Credit: medium.com
Frequently Asked Questions
What Are The Four Types Of Eda?
The four types of Exploratory Data Analysis (EDA) are univariate, bivariate, multivariate, and graphical EDA. Univariate analyzes one variable. Bivariate examines relationships between two variables. Multivariate explores interactions among multiple variables. Graphical EDA uses visual methods to identify patterns.
What Are The Methods Used In Eda?
EDA methods include data visualization, summary statistics, and hypothesis testing. Common tools are histograms, box plots, and scatter plots.
What Is Eda In Big Data?
Exploratory Data Analysis (EDA) in big data involves summarizing datasets to understand their main characteristics. It uses visual methods. EDA helps identify patterns, anomalies, and test hypotheses. It is essential for data cleaning and preparation.
What Is Scalable Data Analytics?
Scalable data analytics refers to the ability to handle and analyze growing data volumes efficiently. It ensures performance and accuracy.
Conclusion
Scalable EDA methods are essential for handling big data analytics efficiently. These techniques streamline data processing and uncover valuable insights. Implementing scalable EDA enhances decision-making and boosts overall productivity. Embrace these methods to stay competitive in the data-driven world. Unlock the full potential of your data with scalable EDA solutions.