

Stand out in data science job interviews with impressive EDA skills. Learn key techniques, practice common interview questions, and discover how to present your EDA projects effectively. Land your dream job!
Understanding EDA is vital for data science roles. It involves summarizing main characteristics and visualizing data for better comprehension. These skills help identify trends, detect outliers, and suggest hypotheses. Proficiency in EDA tools like Python’s pandas and visualization libraries like Matplotlib or Seaborn is essential.
Strong EDA skills demonstrate the ability to handle real-world data challenges efficiently. Practicing with diverse datasets enhances your problem-solving capabilities. Mastering EDA makes you a valuable candidate in the competitive field of data science.
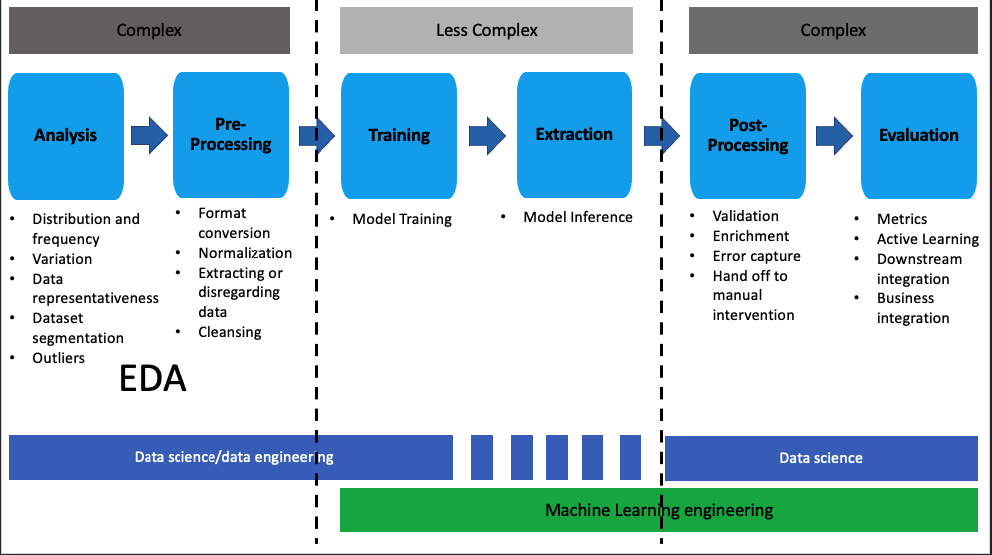
Credit: learn.microsoft.com
Data Cleaning
Data cleaning is a crucial step in the data science process. It ensures the data is accurate and ready for analysis. Without proper data cleaning, you may get inaccurate results. This section will focus on two main aspects of data cleaning: handling missing values and removing duplicates.
Handling Missing Values
Missing values can distort the results of your analysis. Handling them correctly is vital. Here are some common techniques:
- Remove Rows: If a row has too many missing values, remove it.
- Fill with Mean/Median: Replace missing values with the mean or median of the column.
- Forward Fill: Use the last known value to fill missing values.
- Backward Fill: Use the next known value to fill missing values.
Below is an example code snippet in Python:
import pandas as pd
# Load data
df = pd.read_csv('data.csv')
# Remove rows with missing values
df.dropna(inplace=True)
# Fill missing values with mean
df.fillna(df.mean(), inplace=True)
# Forward fill
df.fillna(method='ffill', inplace=True)
# Backward fill
df.fillna(method='bfill', inplace=True)
Removing Duplicates
Duplicate data can skew your analysis. Removing duplicates ensures the integrity of your dataset. Here’s how to do it:
- Identify duplicate rows.
- Remove duplicate rows.
Below is an example code snippet in Python:
import pandas as pd
# Load data
df = pd.read_csv('data.csv')
# Identify duplicate rows
duplicates = df.duplicated()
# Remove duplicate rows
df.drop_duplicates(inplace=True)
Use these techniques to clean your data effectively. Clean data leads to reliable analysis and better insights.

Credit: medium.com
Data Transformation
Data transformation is a crucial step in data preprocessing. It involves converting data into a suitable format for analysis. This process ensures that the data is clean, consistent, and ready for machine learning models. Understanding various data transformation techniques can give you an edge in data science job interviews.
Normalization Techniques
Normalization is essential in data transformation. It scales numerical data to a common range. This helps machine learning algorithms perform better. Here are some common normalization techniques:
- Min-Max Scaling: This technique scales data to a fixed range, usually 0 to 1. The formula is:
(X - min(X)) / (max(X) - min(X)) - Z-Score Normalization: This method scales data based on mean and standard deviation. The formula is:
(X - mean(X)) / std(X) - Robust Scaling: This technique is less sensitive to outliers. It uses median and interquartile range. The formula is:
(X - median(X)) / IQR(X)
Encoding Categorical Data
Categorical data needs to be converted into numerical values. This process is known as encoding. Here are some common techniques for encoding categorical data:
- Label Encoding: Each category is assigned a unique integer. This method is simple but may introduce ordinal relationships.
- One-Hot Encoding: This technique creates a binary column for each category. It is suitable for non-ordinal categorical data.
- Binary Encoding: This method converts categories into binary numbers. It combines the benefits of one-hot and label encoding.
| Technique | Use Case | Formula |
|---|---|---|
| Min-Max Scaling | Data in a fixed range | (X – min(X)) / (max(X) – min(X)) |
| Z-Score Normalization | Standardized data | (X – mean(X)) / std(X) |
| Robust Scaling | Data with outliers | (X – median(X)) / IQR(X) |
| Label Encoding | Ordinal categorical data | N/A |
| One-Hot Encoding | Non-ordinal categorical data | N/A |
| Binary Encoding | Large categorical data | N/A |
Data Visualization
Feature engineering is a key part of data science interviews. It involves creating new features, selecting relevant ones, and transforming data to improve model performance. This process can make or break your machine learning model. Let’s dive into how to excel in this area.
Creating New Features
Creating new features is the art of deriving new variables from existing data. This can give your model an edge. Here are some ways to create new features:
- Interaction Features: Multiply or divide existing features to create new ones.
- Polynomial Features: Raise features to a power (e.g., square or cube) to capture non-linear relationships.
- Date and Time Features: Extract day, month, year, or even day of the week from timestamps.
- Aggregations: Use group-by operations to create summary statistics like mean, max, and min.
Feature Selection Methods
Feature selection is about choosing the most important features for your model. This helps in reducing overfitting and improving performance. Here are some common methods:
- Filter Methods: Use statistical tests to select features. Examples include Chi-square test and ANOVA.
- Wrapper Methods: Use algorithms to evaluate feature subsets. Examples include Recursive Feature Elimination (RFE).
- Embedded Methods: Feature selection is built into the model training process. Examples include Lasso and Ridge regression.
A common approach is to start with filter methods. Then, refine your selection with wrapper or embedded methods. This ensures you have a robust set of features for your model.

Credit: medium.com
Statistical Analysis
Correlation analysis is a vital skill for data science job interviews. It helps in understanding relationships between variables. This section will cover two main aspects: identifying relationships and using correlation matrices.
Identifying Relationships
Identifying relationships between variables is crucial. It helps in predicting outcomes and understanding data patterns. Here are some key points:
- Positive Correlation: Both variables increase together.
- Negative Correlation: One variable increases, the other decreases.
- No Correlation: No relationship between variables.
Understanding these relationships helps in building better models. It also assists in making informed decisions.
Using Correlation Matrices
A correlation matrix is a table showing correlation coefficients. It summarizes relationships between variables. Below is an example:
| Variable A | Variable B | Variable C |
|---|---|---|
| 1 | 0.8 | -0.2 |
| 0.8 | 1 | -0.4 |
| -0.2 | -0.4 | 1 |
Each cell in the table represents a correlation coefficient. The value ranges from -1 to 1. A value of 1 indicates a perfect positive correlation. A value of -1 indicates a perfect negative correlation. A value of 0 indicates no correlation.
Using correlation matrices can help in feature selection. It identifies which variables are highly related. This can reduce the complexity of the model.
Feature Engineering
In data science job interviews, showcasing your EDA (Exploratory Data Analysis) skills can set you apart. Case studies provide a practical context to demonstrate these skills. This section explores real-world applications and interview scenarios to help you prepare effectively.
Real-world Applications
Real-world applications of EDA skills are crucial in data science. Consider a case study where a retail company wants to analyze sales data. Your task is to find trends and patterns. This involves:
- Data Cleaning: Handling missing values and removing duplicates.
- Data Visualization: Creating bar charts to show sales by category.
- Descriptive Statistics: Summarizing data with mean, median, and mode.
Another example is analyzing customer feedback data. You might use text mining to extract sentiment. Here, you could:
- Tokenization: Breaking down text into individual words.
- Sentiment Analysis: Categorizing feedback as positive or negative.
- Word Cloud: Visualizing frequently used words.
Interview Scenarios
In interviews, you may encounter scenarios that test your EDA skills. One common scenario is analyzing a dataset to identify business insights. You might be asked to:
- Load the dataset using Python or R.
- Perform initial data exploration to understand the structure.
- Visualize data distributions using histograms or box plots.
You could also face questions about handling real-world data challenges. For instance, dealing with outliers in a financial dataset. Your approach might include:
- Identifying Outliers: Using box plots to spot anomalies.
- Handling Outliers: Deciding to remove or transform them.
Another scenario could involve feature engineering. You might need to create new variables to improve model performance. Examples include:
- Date Features: Extracting day, month, and year from timestamps.
- Interaction Terms: Combining multiple features to capture interactions.
These scenarios help interviewers assess your practical skills. They also highlight your ability to derive actionable insights from data.
Correlation Analysis
Exploratory Data Analysis (EDA) is crucial for data science interviews. Mastering EDA tools can make a big difference. Here, we discuss some common EDA tools. These tools will help you analyze and visualize data effectively.
Python Libraries
Python offers powerful libraries for EDA. Let’s explore some key ones:
- Pandas: This library is great for data manipulation and analysis. It provides data structures like DataFrame, which is essential for handling tabular data.
- NumPy: Useful for numerical operations and handling arrays. It supports many mathematical functions to perform operations on arrays.
- Matplotlib: A popular plotting library for creating static, animated, and interactive visualizations. It offers a range of plotting functions.
- Seaborn: Built on Matplotlib, Seaborn provides a high-level interface for drawing attractive statistical graphics. It works well with Pandas DataFrames.
- Scipy: Contains modules for optimization, linear algebra, integration, and statistics. It’s essential for scientific and technical computing.
R Packages
R is another popular language for EDA. Here are some important R packages:
- dplyr: A grammar of data manipulation, providing a consistent set of verbs to help you solve the most common data manipulation challenges.
- ggplot2: A powerful and flexible plotting library. It provides a coherent system for creating complex multi-layered graphics.
- tidyr: Helps tidy your data by reshaping and cleaning it. Ensures that your data is in a consistent format.
- readr: Provides a fast and friendly way to read rectangular data. It can handle large datasets efficiently.
- plotly: Creates interactive graphs and can be integrated with ggplot2. This allows for zooming, hovering, and clicking functionalities.
Case Study Examples
Preparing for a data science interview can be stressful. You need to show your skills in EDA (Exploratory Data Analysis). Two effective strategies are mock interviews and portfolio building.
Mock Interviews
Mock interviews help you practice. They simulate real interview scenarios. This boosts your confidence and skills.
You can practice with friends or mentors. Feedback from these sessions is valuable. It helps you improve and identify weak areas.
Consider recording your mock interviews. Review them to find areas for improvement. This will make you more prepared for the actual interview.
- Practice with friends or mentors
- Get valuable feedback
- Record and review sessions
Portfolio Building
A strong portfolio showcases your skills. Include projects that highlight your EDA abilities. This gives interviewers a clear view of your expertise.
Use a variety of data sets in your projects. Show your ability to handle different types of data. This makes your portfolio more impressive.
Include detailed descriptions and visualizations. Explain your process and findings. This helps interviewers understand your approach.
| Project Type | Skills Demonstrated | Data Set Used |
|---|---|---|
| Sales Analysis | Data Cleaning, Visualization | Retail Sales Data |
| Customer Segmentation | Clustering, EDA | Customer Transaction Data |
- Include diverse projects
- Use different data sets
- Explain your process and findings
Frequently Asked Questions
What Are The Eda Techniques In Data Science?
EDA techniques in data science include data visualization, summary statistics, correlation analysis, outlier detection, and data transformation. These methods help identify patterns, trends, and anomalies in data. Use tools like histograms, scatter plots, box plots, and heatmaps for effective EDA.
Is Eda Important For Data Science?
Yes, EDA is crucial for data science. It helps understand data patterns, detect anomalies, and guide model building.
What Skills Are Required For Data Science Vs Data Analytics?
Data science requires skills in machine learning, programming, and statistical analysis. Data analytics focuses on data visualization, SQL, and business intelligence tools.
What Should An Eda Include?
An EDA should include data summary, visualizations, outlier detection, correlation analysis, and missing value treatment.
Conclusion
Mastering EDA skills is crucial for data science job interviews. They help you uncover insights and make informed decisions. Practice these techniques regularly. Enhance your data analysis capabilities and stand out to potential employers. Remember, strong EDA skills can set you apart in the competitive job market.
Good luck!