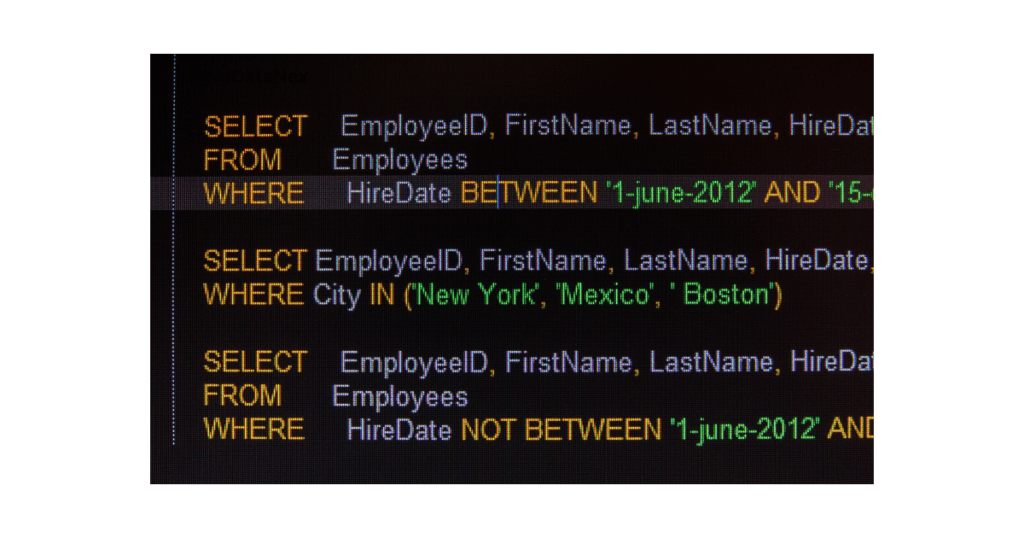
Discover how SQL can revolutionize your feature engineering process. Learn to extract, transform, and load data efficiently for machine learning. Improve model performance with SQL. Click to optimize your ML workflow!
Feature engineering is a critical step in the machine learning pipeline. SQL, a powerful tool for managing and querying databases, significantly aids this process. By using SQL, data scientists can efficiently clean, aggregate, and transform raw data into valuable features.
This data manipulation helps enhance the quality and performance of machine learning models. SQL queries can join multiple tables, filter rows, and create new features based on existing data. Understanding SQL can streamline feature engineering, making it easier to prepare data for analysis and modeling. Effective feature engineering with SQL ultimately leads to more accurate and robust machine learning models.
Introduction To Feature Engineering
Feature Engineering helps improve model accuracy. It transforms raw data into valuable features. Good features make a big difference. They help machine learning models learn better. Quality features lead to better predictions. It saves time and resources. Bad features make models perform poorly. Feature Engineering is a key step in data science.
There are many techniques for Feature Engineering. Normalization scales data to a standard range. One-hot encoding turns categorical data into binary columns. Feature selection chooses the most important features. Feature extraction creates new features from existing ones. Binning groups numeric data into intervals. Interaction terms combine features to capture relationships. Polynomial features add non-linear terms to the model. Imputation fills in missing data. Aggregation summarizes data into groups. These techniques enhance the power of machine learning models.
Credit: news.microsoft.com
Role Of Sql In Feature Engineering
SQL helps in extracting large amounts of data efficiently. It can handle complex queries to filter specific data. Using SQL, you can join tables to get comprehensive datasets. This is essential for building better machine learning models.
SQL is useful for transforming data into the needed format. You can use SQL functions to clean and preprocess data. For example, use functions to remove duplicates or fill missing values. These steps are crucial for effective feature engineering.
Data Cleaning With Sql
Missing values can cause problems in data analysis. Use SQL to identify and handle them. The COALESCE function replaces missing values with a default value. For example: SELECT COALESCE(column, 'default_value') FROM table;. This ensures every field has a value. Another method is using the IS NULL clause to filter out missing data. Example: SELECT FROM table WHERE column IS NOT NULL;. This retrieves only complete records.
Duplicates can skew results. Use SQL to remove them. The DISTINCT keyword helps in selecting unique records. Example: SELECT DISTINCT column FROM table;. Another method is using the ROW_NUMBER function. Combine it with a CTE (Common Table Expression) to delete duplicates. Example:
WITH CTE AS (
SELECT , ROW_NUMBER() OVER(PARTITION BY column ORDER BY id) as row_num
FROM table
)
DELETE FROM CTE WHERE row_num > 1;
This keeps only the first occurrence of each record.
Feature Creation Using Sql
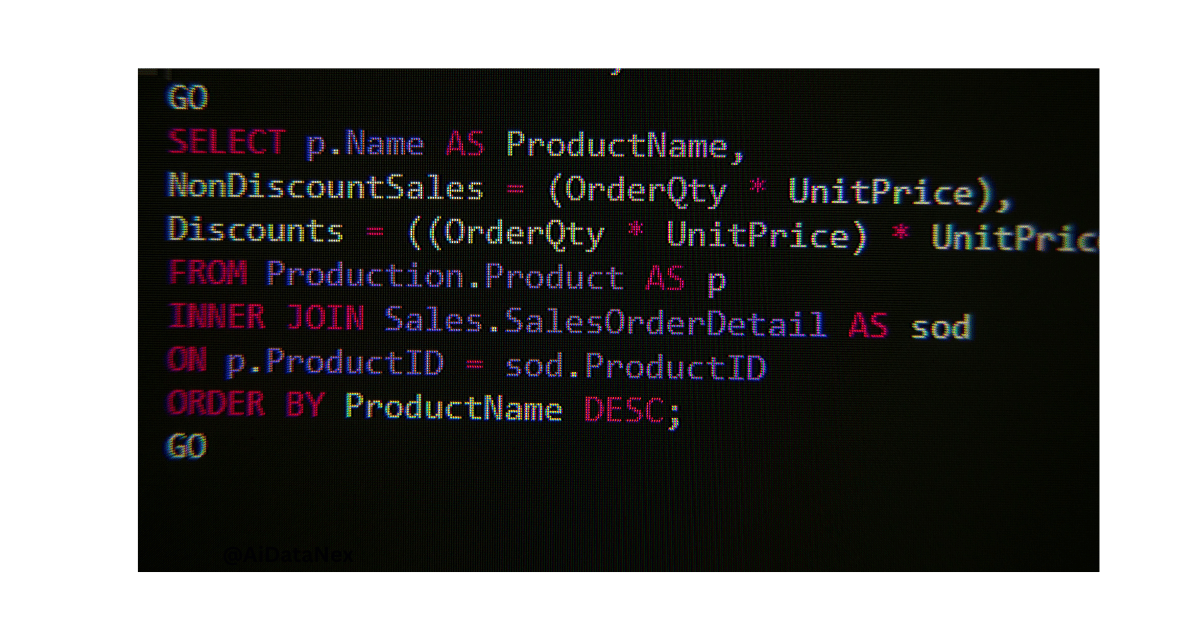
Use SQL to aggregate data from your tables. Group by can help to summarize data. For example, calculate the average purchase amount for each user. This new feature can help models to better understand user behavior. Aggregated features often improve model performance.
Create new features by combining existing columns. Use SQL functions like CASE or COALESCE. For example, create a binary feature to indicate a user’s loyalty status. This can be based on their purchase history. New features can help machine learning models find hidden patterns.
Feature Selection With Sql
Use SQL to filter out unimportant features. This helps to improve model performance.
SELECT only the columns that are relevant. This can reduce the computation time.
SQL can help with dimensionality reduction. Use PCA or t-SNE techniques.
Create views or temporary tables to store reduced datasets. This helps in handling large datasets efficiently.
Optimizing Sql Queries
Indexes help speed up SQL queries. They store a small part of the data. This makes search faster. Use indexes on columns you search often. Avoid too many indexes. They can slow down inserts and updates. Always test performance after adding indexes.
Use SELECT only the columns you need. This reduces data transfer. Avoid SELECT \. Use WHERE clauses to filter data early. This saves processing time. Joins should use indexed columns. It speeds up the queries. Avoid subqueries if possible. Use JOIN instead. Always analyze and optimize slow queries.
Case Studies
Explore how SQL enhances feature engineering for machine learning through detailed case studies. Discover practical applications and real-world benefits.
Real-world Examples
Companies use SQL to clean data. This helps in making better models. For instance, a retail company can use SQL to find popular products. They can use this data to predict future sales.
Another example is healthcare. Hospitals use SQL to track patient data. This helps in predicting diseases early. They can save many lives with this data.
Success Stories
A tech company used SQL for feature engineering. They improved their recommendation system. This led to higher user engagement. The company saw a 30% increase in sales.
Financial firms use SQL to track transactions. This helps in detecting fraud. They can prevent huge losses. Many firms have benefited from this approach.

Credit: openmldb.ai
Best Practices
Use indexes to speed up your queries. Join tables using foreign keys for better performance. Write select statements with only the columns you need. Use subqueries wisely to avoid slowdowns. Avoid using wildcards like `SELECT `. This helps in reducing data load. Normalize your tables to eliminate redundancy. Denormalize only when necessary for performance.
Partition large tables to manage data better. Use views for complex queries to simplify code. Optimize queries for large datasets to save time. Monitor query performance regularly. Use indexes on columns that are frequently searched. Avoid large transactions that can lock tables. Plan for data growth to avoid future issues.
Credit: datascientest.com
Frequently Asked Questions
What Is Feature Engineering In Sql?
Feature engineering in SQL involves creating new features from raw data to improve model performance. It includes tasks like data transformation, aggregation, and normalization to prepare data for analysis.
Is Sql Required For Machine Learning Engineer?
Yes, SQL is essential for a machine learning engineer. It helps in data retrieval, preprocessing, and managing databases.
How Do You Do Feature Engineering In Machine Learning?
Feature engineering involves creating new features from raw data. Techniques include normalization, encoding, and binning. It enhances model performance. Tools like pandas and scikit-learn assist in this process. Prioritize domain knowledge to craft relevant features.
Which Is Better Python Or Sql?
Python and SQL serve different purposes. Python excels in general programming and data analysis. SQL is best for database management. Choose Python for versatility and SQL for querying databases.
Start integrating SQL into your feature engineering process today!