Elevate your data science skills with advanced SQL techniques for big data. Learn complex querying, optimization, and data modeling. Enhance your analytics capabilities.
Big data encompasses enormous volumes of structured and unstructured data. Traditional SQL often struggles with such massive datasets. Complex SQL queries are essential for extracting meaningful insights from this data. These queries utilize advanced techniques like indexing, partitioning, and parallel processing.
They help in optimizing data retrieval, ensuring faster query performance. Effective use of joins, subqueries, and aggregations is crucial. Data analysts and database administrators must possess strong SQL skills. This ensures the ability to manage, manipulate, and analyze big data. Mastering complex SQL queries is vital for businesses leveraging big data to drive decision-making and innovation.

Credit: www.amazon.com
Introduction To Complex Sql
Complex SQL queries play a crucial role in managing big data. They help in retrieving, updating, and deleting large datasets efficiently. Big data involves vast amounts of information. Simple queries often fall short. Complex SQL can handle intricate operations. These queries ensure data is processed quickly and accurately. Understanding complex SQL is essential for data analysts and engineers.
Big data requires advanced data processing techniques. Complex SQL queries can manage and analyze large datasets. They enable the extraction of valuable insights from massive data pools. Efficient data handling is crucial for businesses. It helps in making informed decisions. Complex SQL makes this possible. Data processing becomes faster and more accurate.
Several concepts are key in complex SQL. Understanding joins, subqueries, and indexing is essential. Joins combine data from multiple tables. Subqueries allow nested queries for deeper analysis. Indexing speeds up data retrieval. These concepts form the backbone of complex SQL. Mastering them enhances data handling capabilities.

Credit: medium.com
Advanced Joins
Master complex SQL queries for big data with advanced joins. Combine multiple tables efficiently to uncover valuable insights. Enhance your data analysis skills and optimize query performance.
Inner Vs Outer Joins
Inner joins return rows when there is a match in both tables. Outer joins return all rows from one table and the matched rows from the other. There are three types of outer joins: left, right, and full. Left joins return all rows from the left table. Right joins return all rows from the right table. Full joins return all rows when there is a match in one of the tables.
Self Joins And Cross Joins
Self joins join a table with itself. This is useful for comparing rows within the same table. Cross joins return the Cartesian product of the sets of rows. This means every row from the first table is combined with every row from the second table. Cross joins can generate a lot of data, so use them carefully.
Window Functions
The ROW_NUMBER function gives a unique number to each row. It starts from 1 for the first row. The RANK function also gives numbers to rows. But if rows have the same value, they get the same rank. The next row will skip some numbers. For example, if two rows have rank 1, the next row will have rank 3.
LEAD and LAG functions help to look at other rows in the data. LEAD lets you see the next row. LAG lets you see the previous row. This is useful to compare values in a sequence. You can find trends or patterns in data.
Subqueries And Nested Queries
Subqueries and nested queries enhance complex SQL queries for big data, enabling more precise data retrieval. These techniques allow for efficient data analysis and manipulation within large datasets.
Correlated Subqueries
Correlated subqueries are special. They use values from the outer query. This makes them powerful but slow. They run once for each row in the outer query. Imagine you want to find employees with a higher salary than the average in their department. You use a correlated subquery for this. It compares each employee’s salary to the department’s average. This is useful for detailed comparisons.
Derived Tables
Derived tables are temporary tables. They are created within a query. You can use them to simplify complex queries. They help in breaking down big tasks. For example, calculate total sales per region first. Then, use this derived table to find regions with high sales. This makes your main query cleaner and easier to read. Derived tables are good for organizing data in steps.
Common Table Expressions
Common Table Expressions, or CTEs, help simplify complex queries. They make code easier to read. CTEs use the WITH keyword. Write the CTE first, then the main query. You can reference the CTE just like a table. CTEs are useful for breaking down big tasks. They help in dividing queries into smaller parts.
Recursive CTEs are special. They call themselves. Use them for hierarchical data like family trees. Start with a base query. Then define a recursive query. The recursive query calls the CTE again. This process continues until no more rows are returned. Recursive CTEs make it easy to navigate parent-child relationships.
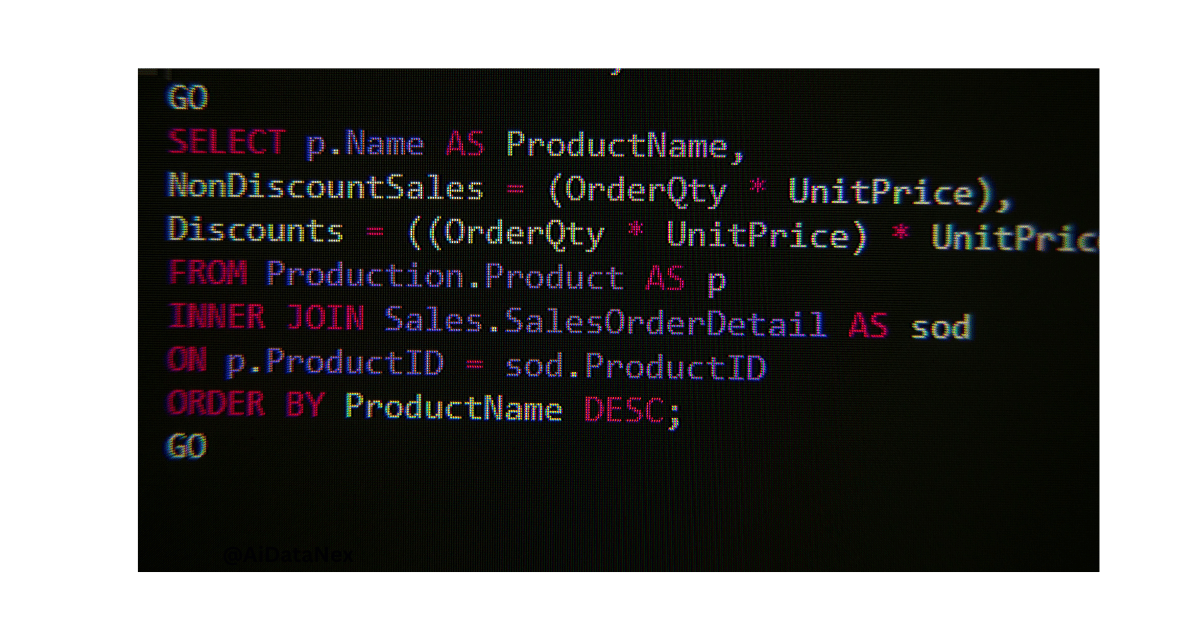
Credit: www.kdnuggets.com
Data Aggregation
Use the GROUP BY clause to group rows that have the same values in specified columns. This helps to aggregate data by those columns. The HAVING clause is used to filter groups based on a condition. It is similar to the WHERE clause but is used for groups. For example, find the total sales for each product where total sales are greater than 1000.
The ROLLUP operator is used for creating subtotals and grand totals in the result set. This helps to summarize data at multiple levels. The CUBE operator is more advanced. It provides a multidimensional summary by computing aggregates for all combinations of columns. This is useful for generating comprehensive reports.
Performance Optimization
Indexes help in speeding up data retrieval. They act like a roadmap for your queries. Create indexes on columns that are often used in WHERE clauses. This can make searches much faster. But, too many indexes can slow down data insertion. So, balance between read and write operations is important.
Execution plans show how SQL queries are run. They help in identifying bottlenecks. Use the EXPLAIN command to see the plan. Look for full table scans as they are slow. Use indexes to avoid them. Check for join operations and see if they are efficient. A good plan can make your queries run much faster.
Real-world Applications
Big data helps companies make better decisions. Complex SQL queries play a key role here. They help analyze large datasets quickly. Retail stores use these queries to understand buying patterns. This helps them stock popular items. Healthcare uses SQL to find trends in patient data. This improves patient care. Finance uses it to detect fraud. Complex queries can spot unusual patterns. Telecom companies use SQL to manage their networks. They find and fix issues faster.
Several tools help run complex SQL queries on big data. Hadoop is a popular choice. It stores and processes large datasets. Spark is another powerful tool. It can handle big data fast. Hive turns SQL queries into Hadoop jobs. This makes it easier to use SQL with Hadoop. Presto is known for its speed. It runs SQL queries on big data quickly. BigQuery by Google is also popular. It is a fully-managed data warehouse.
Frequently Asked Questions
What Are Considered Complex Sql Queries?
Complex SQL queries involve multiple joins, subqueries, nested queries, or advanced functions. They handle large datasets, perform intricate calculations, and require optimization for performance.
Can You Use Sql For Big Data?
Yes, SQL can handle big data. Use distributed SQL databases or integrate with big data tools like Hadoop and Spark.
How To Use Sql With Large Datasets?
Use indexing to speed up queries. Optimize SQL queries for performance. Use partitioning for large tables. Utilize database management tools. Consider distributed databases for massive datasets.
What Are Advanced Sql Queries?
Advanced SQL queries involve complex operations. They include joins, subqueries, nested queries, and aggregate functions. These queries enhance data retrieval, manipulation, and analysis, providing deeper insights.